5. よくある質問(MANUFACIA操作編)
5.1. データをアップロードするとエラーになる
CSVデータ(時系列・振動データ)の場合
扱えるCSVデータは、要求された仕様を満足している必要があります。 詳しくはユーザーズマニュアル -> 使用できるデータ形式を参照してください。
画像データの場合
扱える画像データは、ユーザーズマニュアル -> 使用できるデータ形式に定義されているフォーマットでなくてはなりません。
5.2. 学習・推論に失敗する
学習が失敗したモデルには以下のようにその旨が表示され、モデル詳細は見ることができません。

学習・推論が失敗するケースには以下の理由が考えられます。
アセットアップロード時のタグ付けと、アセットへのラベル付与に矛盾がある
使用しているアセットに対してバッチサイズの指定が大きすぎる
バッチ処理を参照して、アセット数とバッチサイズ、イテレーションの関係について確認してください。
リソースが枯渇している
利用するデータや生成するモデルによっては、MANUFACIAを動かしているサーバーのリソースが枯渇し学習が失敗するケースがあります。リソースが原因の場合、リソースを増やすことで解決する可能性があります。画像データを用いる場合、デフォルトの224x224よりも大きなサイズで前処理を行うことで、ResNet50でのモデル生成時にメモリが枯渇しモデル生成に失敗する可能性もあります。
ヒント
ディスク容量の確認方法は困った時は -> Diskが一杯になったみたいだけど、どのファイルを整理したらいいの?を参照してください。
学習データ、学習の前処理設定の問題
次項の、生成したAIモデルの精度が低いを参照してください。
5.3. アセット追加に時間がかかる
データのアップロード数には制限はありませんが、データ量に比例してアップロードに時間がかかります。アップロード中はブラウザを切ったりしないでください。特に画像データはデータ量や枚数が多くなりがちで、それだけでも処理を重くします。精度とパフォーマンスのバランスを採るためにも、画像の前処理では 512 x 512という上限を設けています。大きなデータを前もって切り出し、縮小することでアップロードの時間を短縮できます。また、ファイルをZIPファイルにまとめることで処理を速くすることもできます。
5.4. 生成したAIモデルの精度が低い
生成したAIモデルの精度が低い場合には以下の理由が考えられます。
学習に必要となるデータが不足している
学習・推論させるデータの種類によっては、学習に使用するデータ量・データの種類が少ないため学習精度が低くなるケースがあります。特に学習に利用するパラメータが多い場合は、正しく学習させるために必要なデータ数も比較的多くなります。
大量のパラメータを少ないデータで学習をしてしまうと、良い結果であったとしても、過学習を起こしている可能性もあるため注意が必要です。データが原因の場合、データ量や種類を増やすことで精度が上がる可能性があります。
目安としては、ラベル当たり100から300のデータは使うようにしてください。教師なし学習においては、検証用の異常データが少ない場合はその限りではありません。
ラベル毎のデータバランスが悪い
学習や検証に用いるデータセットのラベル毎のデータ数に大きな差があると、データ数が多い方の正解率に全体の正解率が大きく影響を受け、正解率の数字は高くとも実際には使えないネットワークになってしまうことがあります。こうした場合には、出来るだけラベル毎のデータセットをバランスよく準備すれば学習が正しく進みます。画像データの場合には、データオーギュメンテーションツールを使ってこのバランスを整えることもできます。
学習(検証)データのラベルが間違っている、もしくはアセットのラベル付けで間違ったタグを定義している。
ラベル付けをする段階での間違い、正しくラベル付けをしたファイルをフォルダ分けする際の間違い、正しくフォルダ分けされたアセットをタグ付けするさいの間違いなども、学習精度が上がらない原因になります。異常検知では学習後、ヒストグラムで、正解ラベルと異常ラベルのサンプルの分布が重なり合っていないかを確認してみてください。
学習に使われているデータが、検証データのバラつきを反映していない
これは学習検証時だけではなく、生成したAIモデルをエッジ機器などで運用し、「正常」「異常」を判別させる時にも同じことが言えますが、学習に使われる入力データの正常なら正常の、異常なら異常のバラつきが、キチンと実状を反映していなければ、ユーザーズマニュアル -> AIの判定についてでも触れているように、生成されたAIモデルは新しいデータを正しく推論することができません。
画像データの場合は、MANUFACIAとは別提供のデータオーギュメンテーションツールを使い、学習に使うデータを元に数種類の画像の特性値を一定範囲内で振らせた画像を複製することができます。学習の入力データのバラツキに幅を持たせることができると、正常と異常の間の境目をよりハッキリさせられ、それが精度の向上に繋がります。
時系列、振動データにおいては、今現在、画像データのようなデータオーギュメンテーションツールの提供はありません。
学習時にどうしても十分なデータがない場合には、AIモデル作成後、データを採りながら再学習をしていくことでAIモデルの精度の向上も期待できます。
前処理でのデータ読込設定が最適でない
時系列、振動データの場合、CSVファイルの読込カラム選択が適切ではなく、サンプルの正常異常を決めるのに大きな意味を持つカラムが選択されていない可能性があります。また、IDや行番号、時間情報などの、学習には特に影響のないデータは学習に用いないように設定してみてください。
前処理のプリセットが最適でない
データの種類によってはプリセットで用意されている前処理をカスタマイズすることで精度が上がる可能性があります。
時系列、振動データの場合には、インターポレートをオンにしてみるとか、ノーマライズ/スタンダーダイズの設定を変えてみる、画像データの場合には中央の対象部分のみをクロップで切り抜くことや、サイズをデフォルトよりも上げることで精度が上がるかも知れません。上記のデータオーギュメンテーションツールと合わせて試してみてください。
特に振動データの場合、時系列データに加えスライディングウィンドウの設定が最適ではないことも精度が悪い原因かもしれません。
設定の変更と学習を繰り返す際には、時系列データの行数が長く(例えば5000以上)やファイル数が多かったり(例えば1000以上)、画像データの場合には画像サイズが大きかったりすると、一回の学習に時間が掛かります。そういう場合には、時系列データの場合にはCSVフォーマットチェッカーを使ってCSV行を間引いて短くしたり、画像データの場合には画像をリサイズして小さくすることで、学習時間を短縮して、前処理の変更が学習にどのような影響があるのかを効率よく試すことができます。
前処理の設定の仕方は、お使いのデータセットの種類に応じて ユーザーズマニュアル -> 前処理を設定する(時系列、振動データ)、もしくは、ユーザーズマニュアル -> 前処理を設定する(画像データ)を参照してください。
モデルの生成数が少ない
前処理画面で設定できる以外のハイパーパラメータ(エポック数、学習率等)はランダムで設定されます。したがいまして、全く同じ条件で学習させても電卓のように全く同じ答えになるわけではありません。ある程度のモデル数を生成しないと良い精度のモデルが出来ません。まずは少ないモデル数(10~20)で学習がキチンと流れることを確認することをお勧めします。
精度を更に上げたい場合や、学習に失敗したモデルが多発するような場合には、後述する前処理のパラメータを少しづつ(一度に一つだけ)変えながら良さそうな傾向の設定を確認した後で、最後にモデル数を少し多くして学習させてみてください。(50から100程度)
生成するモデルを増やしても、精度が変わらない、もしくはMCCの値が1.0に近づかない場合には、データセットが少な過ぎるか、またはデータセットに一部間違ったラベルのサンプルが混入している可能性もあります。もちろん、MANUFACIAで扱うのが難しいデータであることも否定はできません。
全てのモデルが学習に失敗するような場合には、入力データのフォーマットに問題があることも考えられます。CSVファイルをお使いの場合にはCSVフォーマットチェッカーを利用して、フォーマットに問題がないかを確認してください。
5.5. どのAIモデルがいいのかよく分からない
一般的に「accuracy(正解率)」が高く「学習誤差」が低いモデルが、良いモデルだと言われていますが、学習に用いたデータセットのファイル数や、同じクラスとしてラベル付けされているデータファイルがどのようなバラツキ(分布)になっているのかなどもモデルの良し悪しに影響します。 V2.2にて新しく導入した、AIモデルの評価指標であるMCC(マシューズ相関係数)により、正解率からだけでは見誤るようなケースでも使えないモデルを見定めることができるようになりました。
良いモデルの見極めをする際のポイントは、
「MCC(マシューズ相関係数)」が1.0に近いこと。
AUCが1.0に近いこと。
検証データのクラス毎の分布が綺麗に分かれていること。(異常検知の学習後に、クラス毎の分布が重なり合っていないかをヒストグラムで見ることができます)
「学習誤差」が低いこと。(学習誤差曲線が、学習が進むにつれてゼロに収束している)
上記の項目で差がなければ、よりネットワークサイズが小さいこと。
異常検知の場合は、「正常」「異常」を判断するしきい値をモデル生成後に調整することも可能です。例えば、「異常」データの推論精度を上げたい場合は、しきい値を小さい値に調整することで「異常」データの見逃しを下げる設定にすることが可能です(モデルよっては変更できないものもあります)。
学習が正しくできていないモデルは選択肢から外します。以下のパターンは学習が正しくできていないものです。
「モデル一覧」画面で、正解率・学習誤差が表示されていないもの。
MCCが0.5を下回るもの。(ランダムでクラス予測をするよりも悪い)
しきい値や距離がゼロのもの。
学習誤差曲線が学習と共にゼロに収束していないもの。
スムースグラッドが黒い画面のみのもの。(教師あり学習時のみ)
5.6. 学習の一時停止が出来ない
MANUFACIAに実装されている学習の一時停止機能については、ユーザーズマニュアル -> モデルを学習させるを参照してください。
5.7. データを追加してAIモデルを再度生成したい
データを追加してAIモデルを生成したい場合は、プロジェクトを新規に生成する必要があります。手順としては、該当のラボを選択し、アセットを登録するで、データを追加し、プロジェクトの新規登録で新しくプロジェクトを作成して新規でAIモデルを生成します。
5.8. アセットに付与したタグを変更したい
既に登録しているアセットのタグを変更したい場合は、登録済みのアセットのタグを変更することはできないため、改めてラボを作成し、アセットを登録する際に希望のタグを設定してください。
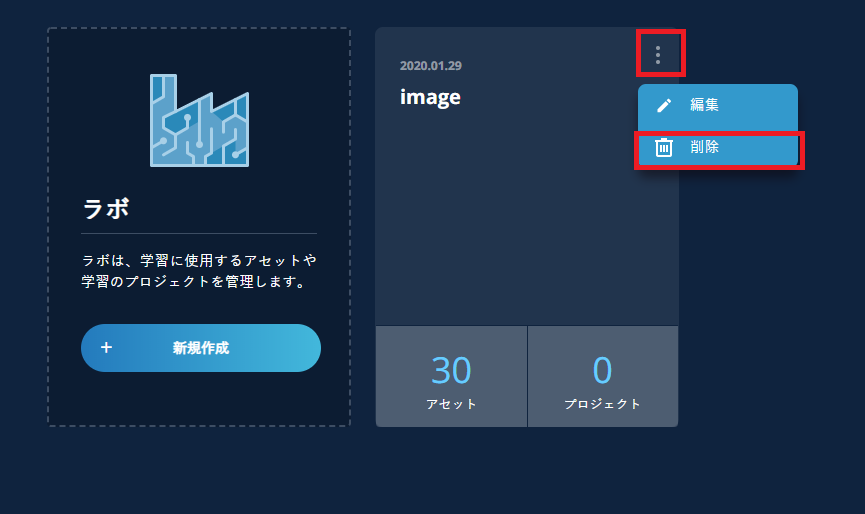
5.9. ラボを削除したい
ラボを削除するには、そのラボ内に登録されているプロジェクトを先に全て削除する必要があります。なお、アセットが登録されていてもラボを削除することはできます。 ラボの削除は、対象ラボの右上にある三つの点をクリックし、「削除」を選択しておこないます。
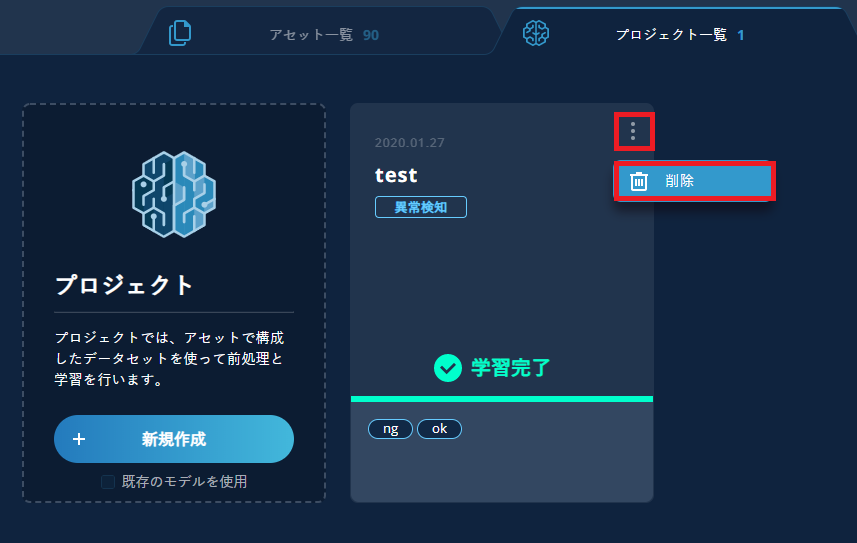
5.10. プロジェクトを削除したい
その削除対象のプロジェクトが、別のプロジェクト作成の際に【既存のモデルを使用】として利用されていないことが前提です。その際には、先にそれらのプロジェクトを削除する必要があります。
プロジェクトの削除は、対象プロジェクトの右上にある三つの点をクリックし、「削除」を選択しておこないます。
5.11. アセットを削除したい
現在、アセットの削除には対応していません。
5.12. モデル一覧にモデルがプロットされない
モデル一覧にモデルがプロットされていない場合があります。学習誤差は100をmaxの閾値としているため、100以上の値やN/Aの場合はグラフにプロットされません。
5.13. ラベルが追加出来ない
ラベル付与のステップでは、ラベルは最大20まで登録できます。21を超える場合は、「+ラベルの作成」が表示されず、追加はできません。