4. MANUFACIAを使ってみよう3
4.1. プロジェクトを評価する
4.1.1. AIモデルを選択する1
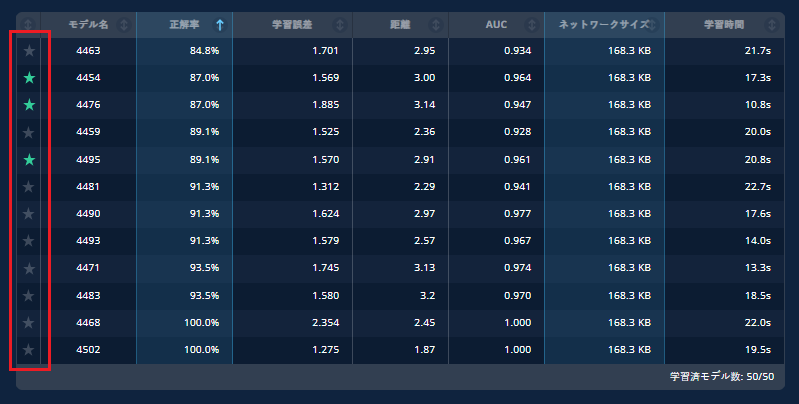
作成したモデルの学習結果は、横軸が正解率、縦軸がネットワークサイズの散布図に表示されます。

散布図の下には、モデル毎の主要な結果がテーブル内に表示され、カラム毎にソートが可能です。
散布図内のマーカー(モデル)、またはテーブルの行をクリックすると、そのモデルの詳細が表示されます。学習が失敗したモデルには「学習に失敗しました」と表示され、詳細結果細表示はできません。また、演算処理で正常な計算が行われなかった場合、例えばゼロによる除算や、結果が無限大になる場合には、一部の結果が空白になることがあります。
ちなみに
散布図の縦軸、横軸の設定を変えるときは、軸のタイトルをクリックします。
4.1.2. AIモデルを選択する2
モデル一覧画面からあるモデルの詳細表示をさせた後、画面の右上にある(モデル番号/全モデル数)表示の両脇にある【<>】キーをクリックすることで、表示されているモデルの前後のモデルの詳細を表示することができます。選択したモデルで学習が失敗した場合には、詳細は表示されません。
ちなみに
検証データのサンプル数が多くなると、それにつれてモデル詳細表示に時間がかかります。
注意
MANUFACIA v2.2以前に作られたモデルの学習結果をv2.2上で見る場合、v2.2とは違う方法でしきい値や距離が計算されていますので、モデル一覧画面と、モデルの詳細表示での正解率、しきい値や距離などが異なることがあります。
この場合には、混同行列の下のスライダ上の【自動】ボタンを押すことでv2.2の計算方法に合わせることができます。
4.1.3. AIモデルを評価する
AIモデルの学習結果として詳細表示されるのは、
これらについて、以下更に詳しく解説をします。
4.1.3.1. ネットワークの各評価指標

数式中のTP (True Positive), FP (False Positive), FN (False Negative), TN (True Negative) については、次項「混同行列」を参照のこと。
ちなみに
演算処理で正常な計算が行われなかった場合、例えばゼロによる除算や、結果が無限大になる場合には、一部の結果が空白になることがあります。
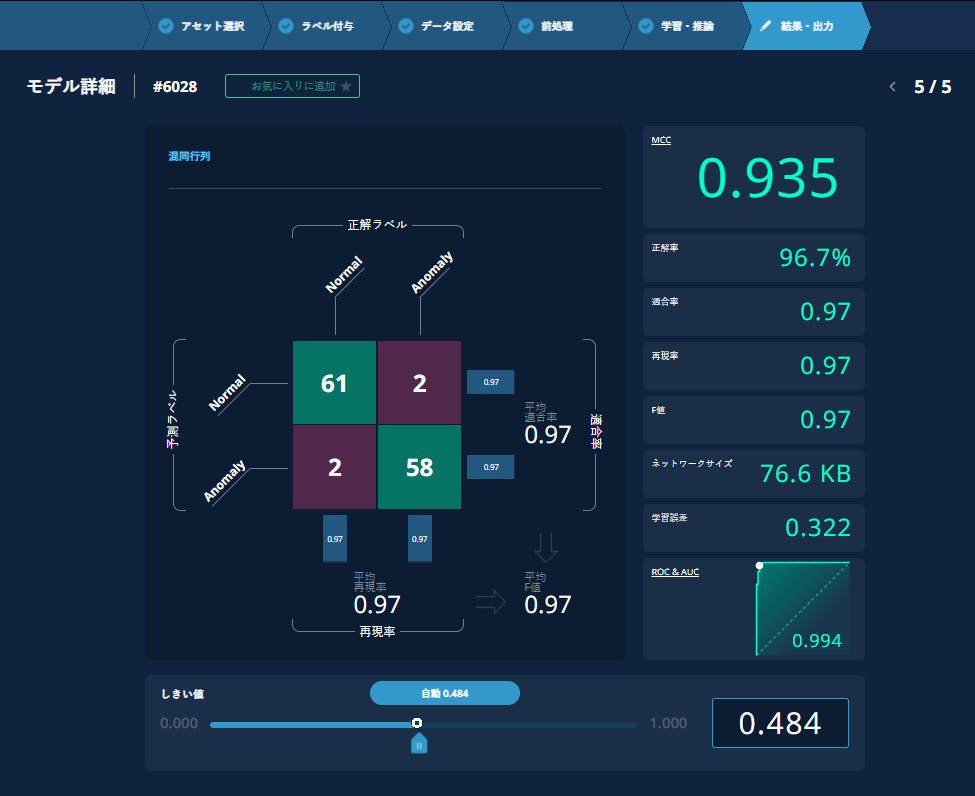
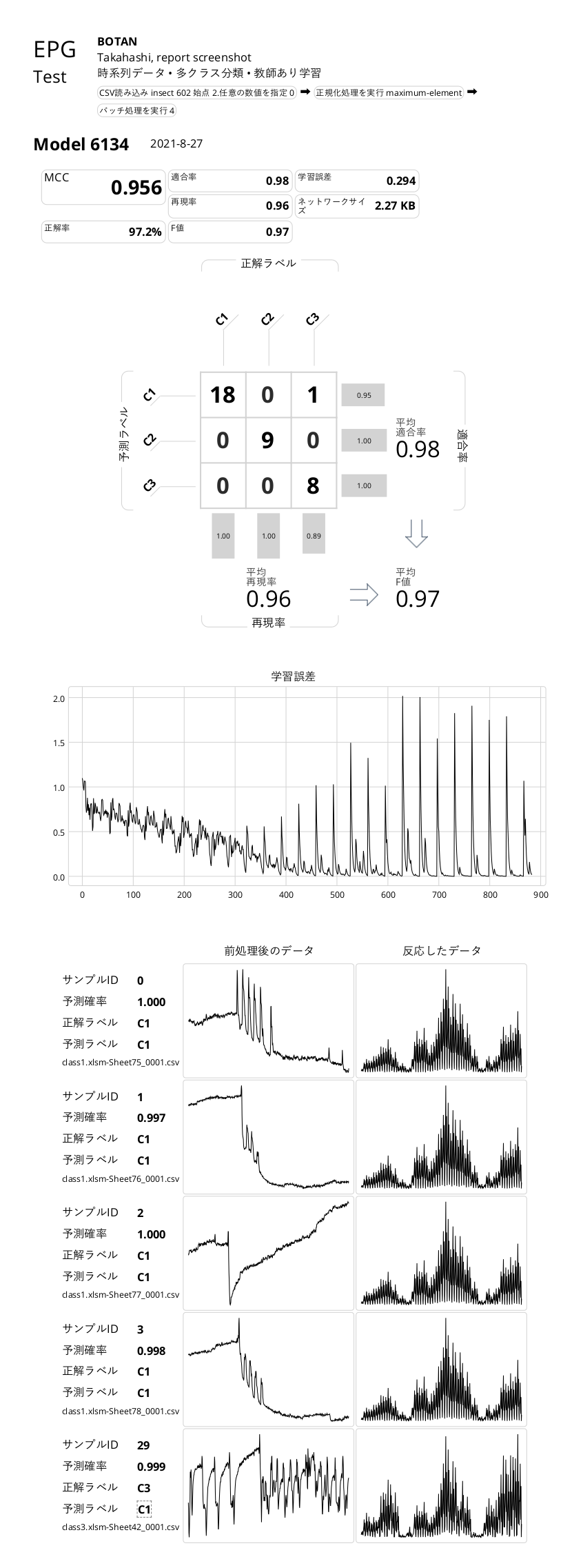
MCC
マシューズ相関係数(Matthews Correlation Coefficient)のこと。この指標は、2値分類(異常検知)においては-1.0から1.0の値をとり、1.0に近くなるほどネットワークが学習通りの予想をしていると考えてよく、0.0に近い場合はランダムで正常/異常を判断するのと同等、-1.0に近くなる場合には、AIの予想が全く逆になっていると判断することができます。
この指標の定義は2値分類においては
\(MCC = \frac{TP \times TN – FP \times FN}{\sqrt{(TP + FP)(TP + FN)(TN + FP)(TN + FN)}}\)
また、多クラス分類においては以下のように定義されています。クラスが2つ以上ある場合には最小値は-1.0ではなく、クラスの数に応じて-1.0と0.0の間の値を採りますが、最大値は常に1.0です。
\(MCC = \frac{\sum_{k} \sum_{l} \sum_{m} C_{kl} C_{lm} - C_{kl} C_{mk}}{\sqrt{\sum_k (\sum_l C_{kl})(\sum_{k'|k' \neq k} \sum_{l'} C_{k'l'})}\sqrt{\sum_k (\sum_l C_{lk}) (\sum_{k'|k' \neq k} \sum_{l'} C_{l'k'})}}\)
注釈
マシューズ相関係数に関するWikipediaページ(英語)
正解率(Accuracy)
全ての予想の正解率のことで、混同行列の正解数の和を全要素の総和で割ったものになります。この指標は後述する再現率、適合率などと一緒に評価するものですが、特にラベル毎のデータ数に偏りがある場合には、正解率が100%に近くなったからといって必ずしもよいネットワークであるとは言えないこともあるので注意が必要です。 例え全体のデータ数が多くても、学習に用いたデータが他のラベルに比べて極端に少ないラベルを正しく予測するのが難しくなります。
\(Accuracy = \frac{TP + TN}{TP + FP + FN + TN}\)
再現率(Recall)
実際に「正常」であるもののうち、「正常」と予想された割合のこと。
\(Recall = \frac{TP}{TP + FN}\)
適合率(Precision)
「正常」と予測したもののうち、実際に「正常」である割合のこと。
\(Precision = \frac{TP}{TP + FP}\)
F値(F-measure)
適合率と再現率の調和平均。
\(F\)-\(measure = \frac{2}{Recall^{-1} + Precision^{-1}} = \frac{2 \times Precision \times Recall}{Precision + Recall}\)
学習誤差
ここに表示される学習誤差は、学習誤差曲線の学習開始から終了までの平均値です。
ネットワークサイズ
ネットワークサイズは、生成されたネットワークのファイルサイズです。ネットワークが複雑になればネットワークサイズも大きくなり、処理にも時間が掛かります。
ROC曲線とAUC
ROC曲線は、正常と異常とを分ける値(カットオフ値)をプロットし線で結んだもので、横軸を偽陽性率、縦軸を真陽性率とし、それぞれ0.0から1.0までの値を採ります。この時にROC曲線下の面積をAUCとして表します。良いモデルであればAUCが大きくなり、悪いモデルの場合はAUCは小さくなります。
AUCの最大値は1.0、最小値は0.0となり、ランダムで正常と異常を分ける様なモデルであればAUCは0.5程度になります。AUCが最大の1.0を採る際には、ROC曲線は偽陽性率と真陽性率からなる座標がそれぞれ (0.0, 0.0) と (0.0, 1.0)、そして (0.0, 1.0) と (1.0, 1.0) を結ぶ2本の線分から出来上がります。
4.1.3.2. 混同行列
混同行列(Confusion Matrix)はアルゴリズムの性能を可視化するテーブルで、MANUFACIAでは正解ラベルはテーブルの列、予測ラベルはテーブルの行として表示されています。
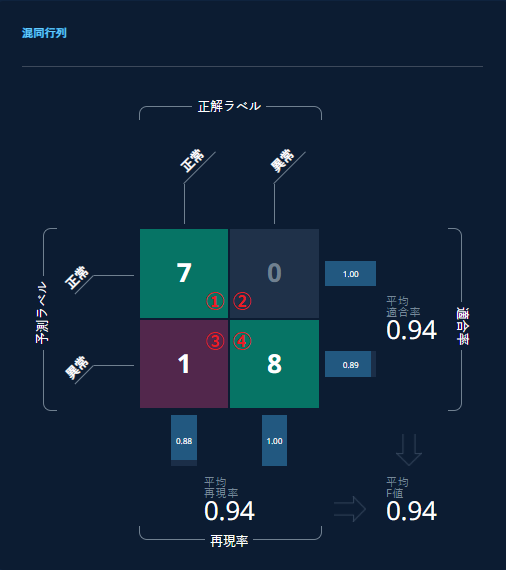
(1)「正常」データを、AIモデルが「正常」と判断した正答数(真陰性=True Negative)
(2)「異常」データを、AIモデルが「正常」と判断した誤答数(偽陰性=False Negative)
(3)「正常」データを、AIモデルが「異常」と判断した誤答数(偽陽性=False Positive)
(4)「異常」データを、AIモデルが「異常」と判断した正答数(真陽性=True Positive)
混同行列の下にあるスライダで、異常検知教師あり学習の場合にはクラス間のしきい値を、異常検知教師なし学習の場合には「正常」からの距離を調整することが出来ます。(ヒストグラム参照)この調整によって混同行列と各評価指標も変わり、この調整後の値がモデルに使用されます。
このしきい値と距離は、\(FPR^2 + FNR^2\) の値が最小になるROC曲線上の点として計算されます。ここで、FPRはFalse Positive Rate (誤検出率), FNRはFalse Negative Rate(未検出率)のことです。

ヒント
スライダ上の【自動】ボタンを押すと、しきい値や距離をいつでも初期設定に戻すことができます。
混同行列の右と下にはそれぞれ予測ラベル毎の正解の割合(適合率)、正解ラベル毎の正解の割合(再現率)が棒グラフで表示されています。さらに以下の計算式で求められた平均再現率、平均適合率、平均F値が表示されます。
平均再現率 ... 正常、異常それぞれの再現率の平均
平均適合率 ... 正常、異常それぞれの適合率の平均
平均F値 ... 平均再現率と平均適合率を用いた調和平均
注意
多クラス分類においては、しきい値の変更はできません。
4.1.3.3. ヒストグラム
ヒストグラムは、異常検知の教師あり/教師なし学習において、検証データの予測結果の分布と、「正常」と「異常」ラベルのしきい値または距離を示したものです。教師あり学習の場合は、学習中に「正常」と「異常」ラベルのデータがどのように分離されたか、教師なし学習の場合は、「異常」ラベルが「正常」グループの分布中心からどれくらい離れているかを確認することができます。
ヒストグラムのタブをクリックすることで、混同行列の代わりにヒストグラムを表示することができます。 ヒストグラム中央の水平線より上には「正常」ラベル、下には「異常」ラベルの結果が表示されています。混同行列同様、検証結果が正解の場合には緑色、不正解の場合には赤色で表示されます。自動で計算されたしきい値または距離は白の点線で表示されています。
下のスライダでヒストグラムの垂直線を動かすことができ、「正常」(左)と「異常」(右)のしきい値または距離を、サンプルの分布を見ながら微調整することができます。値を調整した場合は、調整後の値がモデルに使用されます。
理想的なモデルでは、中央の水平線より上の「正常」ラベルの分布と、水平線の下の「異常」ラベルの分布が左右にいくらかの間隔を持っています。その間隔のところにしきい値または距離を設定することで、画面上のサンプルは全て予測が正解として緑色で表示されます。こちらの図も参照ください。

注意
ヒストグラムは一定の幅でしきい値や距離を区切って、その範囲に入るサンプルの数をバー表示しています。自動で計算された数値と各領域との位置関係によって、正誤を表すバーの色が反転することもありますのでご注意ください。
4.1.3.4. 検証サンプル一覧
このテーブルには、検証データを用いた予測結果が表示されています。混同行列の要素をクリックすることで、選択された要素だけを表示することができます。
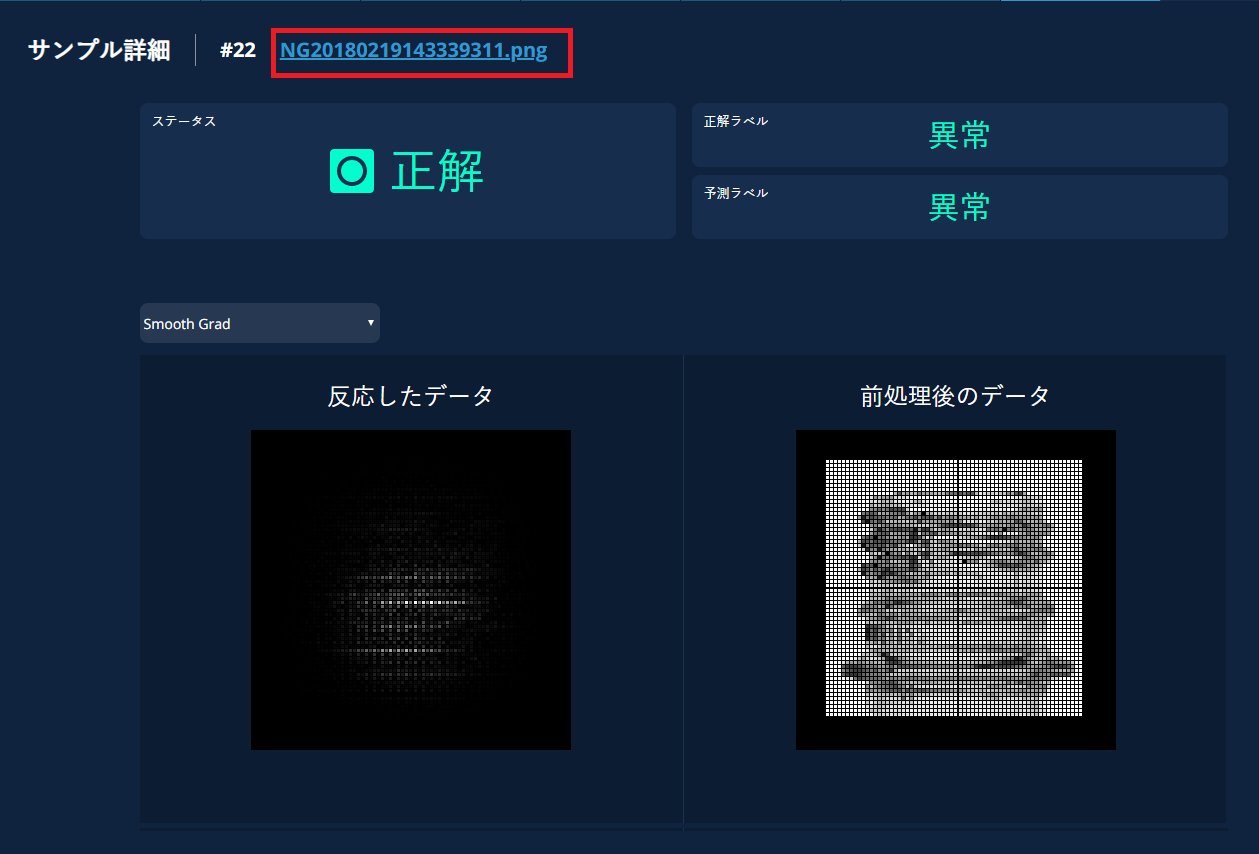
また、検証サンプルのテーブルの任意の行をクリックすると、そのサンプルのファイル名、予測ラベルと共に、前処理後のデータと特徴を可視化したデータを比べて見ることができます。

異常検知教師あり/多クラス分類の場合
異常検知教師あり学習と多クラス分類においては、前処理後のデータと共に、畳み込みニューラルネットワーク(CNN)が画像のどこに注目しているかを可視化するSmoothGrad手法を用いて処理をした画像が表示されます。
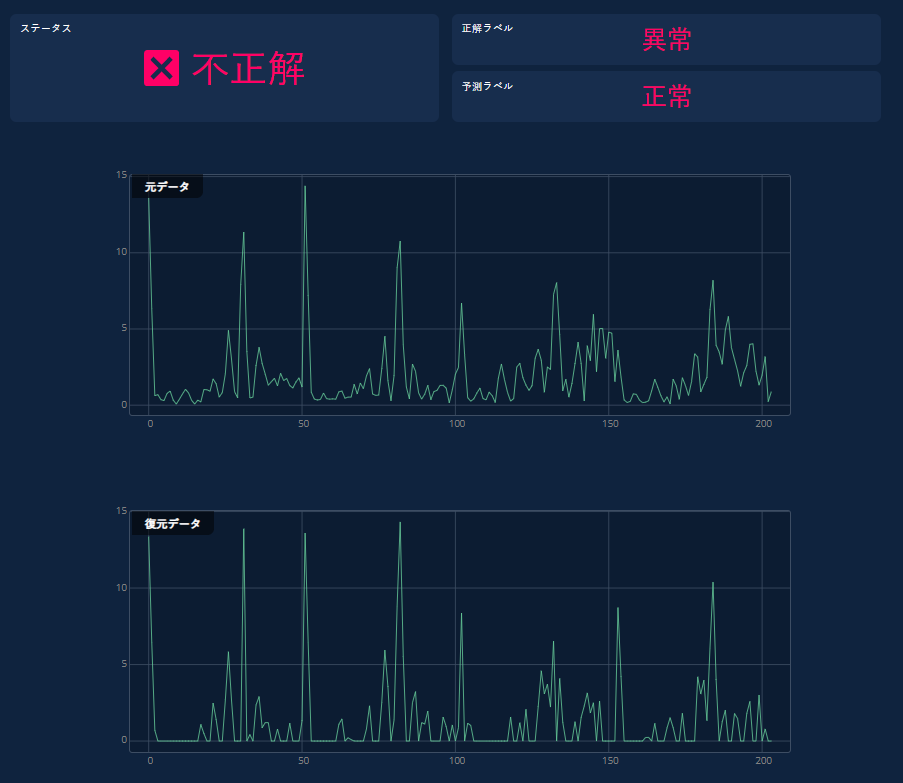
異常検知教師なしの場合
異常検知教師なし学習においては、前処理後のデータと復元データが表示されます。復元データにおいて、前処理後のデータと同じように復元できていないところが「正常」データから離れているところという理解をしてください。
注意
学習が上手く進まなかったいくつかのモデルでは、内部演算処理でエラーが発生しSmoothGradがエラーメッセージと共にただ黒く表示されるだけのこともあります。
ちなみに
時系列データや振動データを使った学習では、前処理後のデータ、SmoothGradもしくは復元データが、前処理で選択したカラムの内容を左から順に一本の線に連結した形で表示されます。
4.1.3.5. 学習誤差曲線
学習誤差曲線は、学習を進めて行くにつれてどのように誤差が小さくなり、更に学習を進めて行くと過学習となって誤差が増えていくという傾向を示す線図です。この図ではX軸がイテレーション数(ステップ数)注、Y軸が誤差を示しており、曲線の右肩にある【平滑化】のバーを動かすことで、山や谷を平滑化して除いた曲線のベースラインのトレンドを見ることができます。
注釈
イテレーションは、データセット(アセット)の数とバッチサイズから自動的に決まります。例えば、データセットが1000ある場合でバッチサイズが4の場合、1000/4 = 250の小さなサブセットに分けたデータセットが学習に使われます。この250がイテレーション数になり、全てのデータセットを一度づつ使う学習の単位が1エポックと定義されています。
仮に混同行列での評価(MCCや正解率など)が良かったとしても、この学習曲線がゼロに近づくようにして安定することのないモデルであれば、実際に使えるかどうかは怪しいです。どうか、この曲線のトレンドにも注目してください。

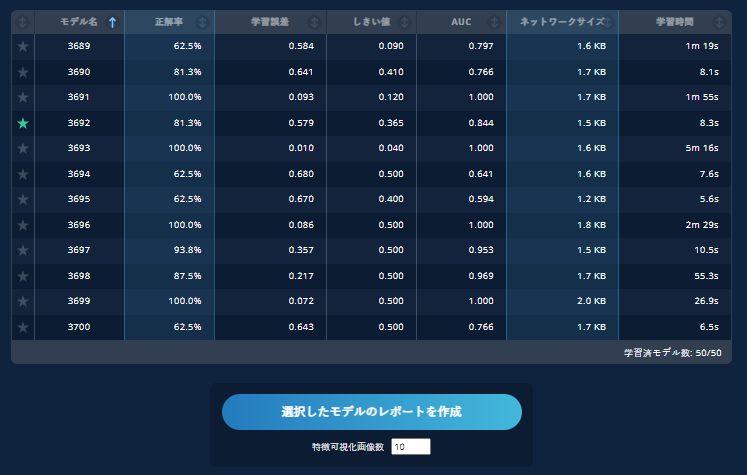
4.1.3.6. レポートを作成する
モデル一覧のテーブル内でモデルにお気に入りのマークを付けた上で、【選択したモデルのレポートを作成】をクリックすることで、モデル詳細画面の内容とサンプル詳細、各種チャートを新規タブに作成することができます。
サンプル詳細は、正解ラベル、予測ラベル表示と共に、教師ありの場合にはSmoothGrad、教師なし学習の場合には復元データが前処理後のデータと一緒に表示されます。【選択したモデルのレポートを作成】ボタンの下にある【特徴可視化画像数】(初期値は10)を選択することで出力数を定義することができます。
異常検知の場合は、以下の3つを出力数の1/3づつ出力するようにサンプル数の上限が決められ、
異常ラベルを異常と判断したサンプル (TN)
正常ラベルを異常と判断したサンプル (FN)
異常ラベルを正常と判断したサンプル (FP)
条件に見合うサンプルを、サンプルIDの小さいものから選択します。それでもなお実際の出力数が指定した出力数を下回る場合には、残りを
正常ラベルを正常と判断したサンプル (TP)
から選んで出力します。
また、多クラス分類の場合には、AIの判断が不正解のサンプルを定義された出力数分ランダムで選択します。
レポート例:
ヒント
サンプル詳細の出力順序は、サンプルIDの順になります。
4.2. AIモデルを活用する
本項では、MANUFACIAで学習させたAIモデルを使って推論をさせるために必要なステップについて説明します。
4.2.1. AIモデルをデプロイする
使用するモデルが決まったら、モデルの詳細画面の一番下にある、【このモデルを使用する】をクリックします。
【このモデルを使用する】は、MANUFACIAサーバーのMQTT ブローカに推論対象が接続されていない場合には、有効(水色)になりません。その場合に、これを有効にするには以下の2つの方法があります。
AIモデルテスターを起動し、MANUFACIAに対して接続を確立する。
Greenia Embedded SDKのサンプルアプリ(sampleApp)を起動し、MANUFACIAに対して接続を確立する。
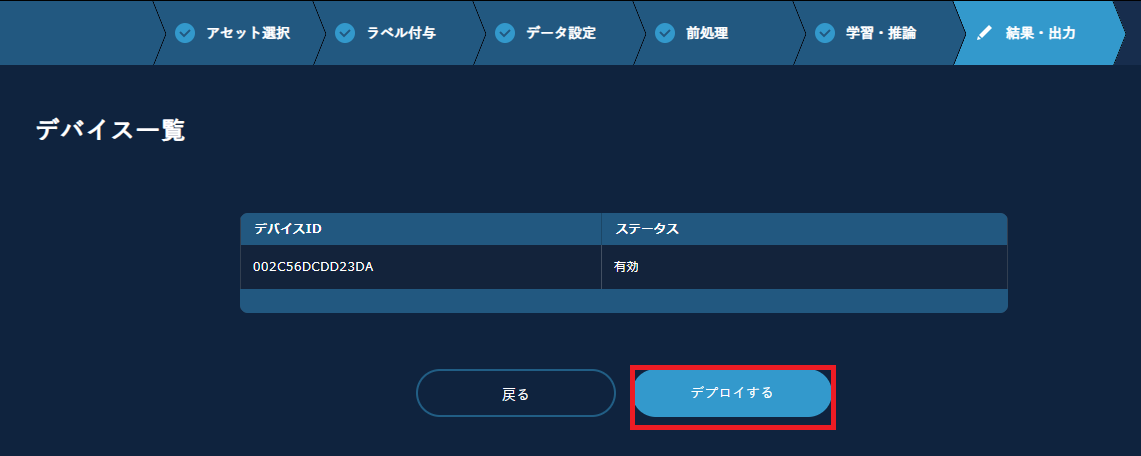
次の画面では、サーバーに接続されているデバイスがすべて表示されます。目的のデバイスが表示されていること確認して【デプロイする】をクリックします。
注意
MANUFACIAがインストールされているサーバーに接続されているデバイスのうち、カートリッジが空のデバイスにのみデプロイされます。
ステータスが「installed」になれば、デバイスにインストールされた状態です。これ以降は、デバイス側での作業になります。

4.2.2. AIモデルをテストする
MANUFACIAで生成したAIモデルを使い、新規のテストデータで推論させることができます。詳しくは「AIモデルテスターユーザーズマニュアル」を参照してください。
4.2.3. AIモデルをシステムに組み込む
生成したAIモデルを実ライン等で運用する場合には、別途Greenia Embedded SDK、もしくはPython APIを使ってシステムを構築する必要があります。
4.2.4. AIモデルを再学習する
MANUFACIAでは、作成したAIモデルにアセットを追加して再学習することができます。再学習では、前処理は固定されており、アセットのみを変更することができます。過学習になることを避けるため、初回学習時のアセットは学習に利用しないことを推奨します。そのため、追加分のアセットは全クラス分が必要です。
再学習はラボ単位で行い、ラボ内で「お気に入り」をつけた全てのモデルが再学習の対象となります。再学習の設定は以下の手順で行ってください。
4.2.4.1. お気に入りに追加・お気に入りから削除する
再学習したいモデルをモデル一覧から選択します。選択方法はモデル名の横にある「☆」をクリックします。追加済みとなると「☆」に色がつきます。追加済みの「☆」をクリックすると解除されます。モデル詳細画面の左上のラベルでも「お気に入り地の追加・解除」ができます。
4.2.4.2. ラボにアセットを追加する
再学習をさせたいプロジェクトが格納されているラボにアセットを追加します。アセットの追加は、アセットを登録するを参照してください。アセットは全クラス分追加することを忘れないでください。
4.2.4.3. プロジェクトを作成する
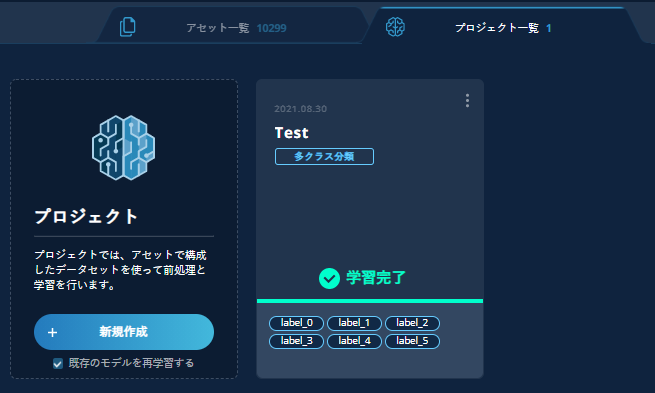
再学習時の場合にも新しいプロジェクトが必要です。【既存のモデルを再学習する】にチェックを入れて、【+ 新規作成】ボタンをクリックします。このチェックを入れることで、全ての前処理設定が変更できないプロジェクトが作成されます。
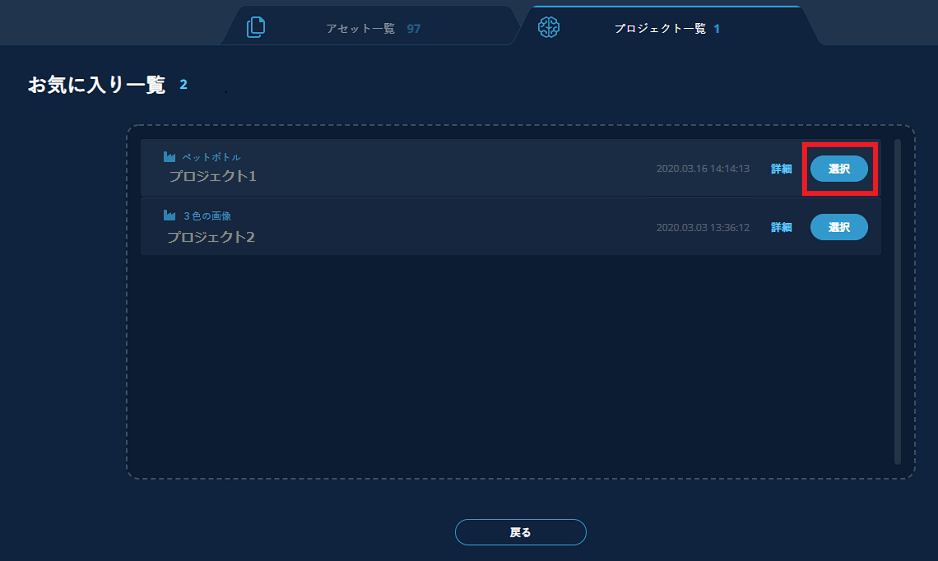
お気に入り一覧画面が開き、お気に入り登録があったすべてのプロジェクトが表示されます。該当のプロジェクトの【選択】をクリックします。
プロジェクトの作成画面が立ち上がりますが、「選択したプロジェクト名_コピー」というプロジェクト名が入力されているので、任意の名前に変更し、名前を変更して作成をクリックします。「元の名称で作成」を選ぶと、名前を変更しないで新しいプロジェクトを作ります。

4.2.4.4. アセットの追加
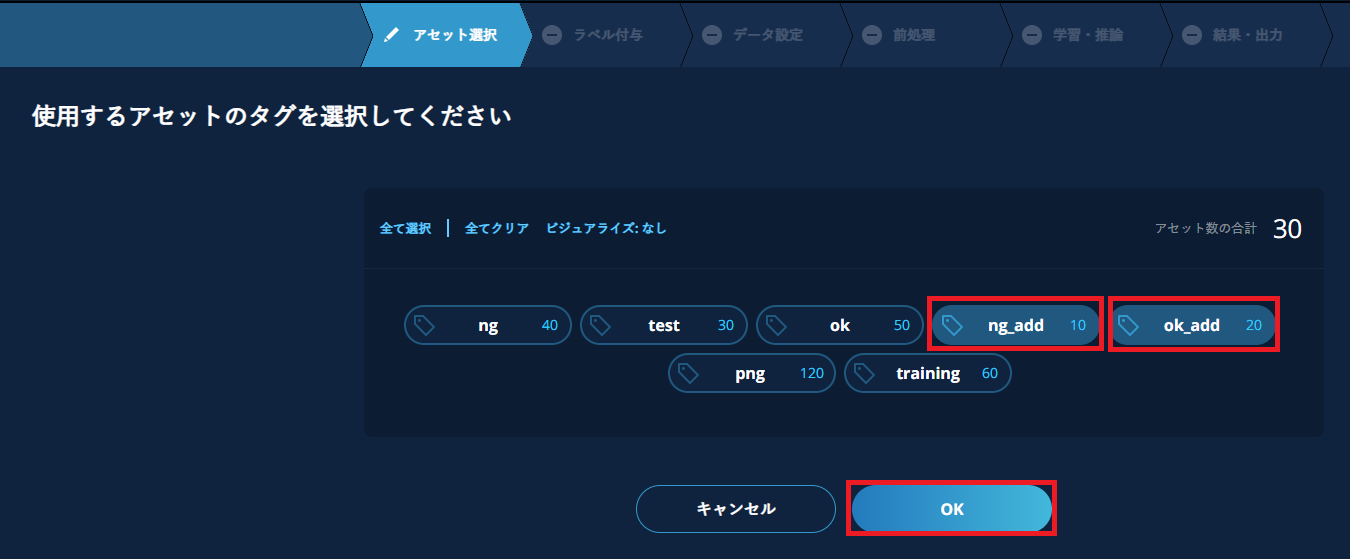
使用するアセットの選択画面が表示されます。アセットは前回の学習で使われた全クラス分を用意してください。 初回学習時に使用したアセットは選択済みになっていますが、それらのチェックを外して今回使用するアセットのみ選択します。 追加アセットが全クラス分ない場合は、不足するクラス用のアセットとして初回学習時に使用したアセットを使用することができますが、推奨いたしません。
アセットを選択後、【OK】をクリックします
ラベル付与の画面では、初回学習時のラベル設定を削除し、今回利用するタグのラベルを付与します。
再学習では前処理内容を変更できませんが、それ以外は通常の学習と同じです。