1. MANUFACIAをお使いいただく前に
1.1. MANUFACIAで使われる用語
アカウント
ラボを作成するために、あらかじめ用意されている12個の作業スペース。アカウントごとの権限の制限はありません。
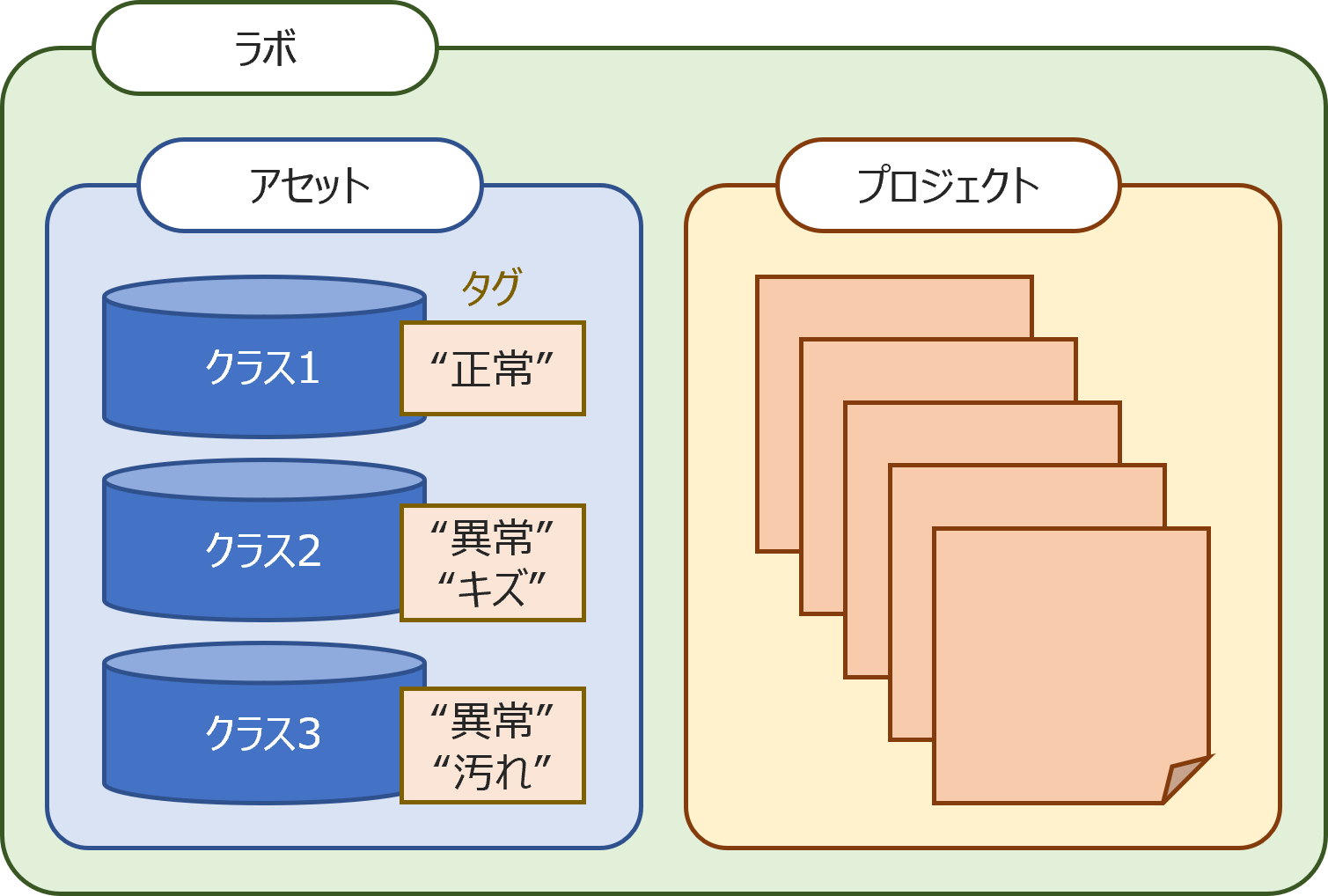
ラボ
学習、検証をするためのデータ及び学習結果をまとめておく場所です。
アセット
学習、検証に使用するファイルです。
プロジェクト
AIモデルを作成する場所です。アセットに登録したデータセットを使って前処理と学習を行います。学習の結果もここに保存されます。
クラス
分類するまとまりです。
ラベル
クラスの名称です。異常検知の場合は「正常」「異常」のというラベルが用意されています。多クラス分類の場合は、クラス数に応じたラベルを設定します。
タグ
MANUFACIAで扱うアセットのまとまりの分類名。(詳細はタグの設定 を参照)
モデル・AIモデル
学習によって生成される、ニューラルネットワークとデータの処理方法などが定義されたもの。
デプロイ
生成したモデルを運用環境のエッジデバイスなどに送信すること。
1.2. MANUFACIAでできること
MANUFACIAは、正しくクラス分類されたアセットからクラス毎の特徴を学習し、それをニューラルネットワーク(AIモデル)として構築します。そのAIモデルを機器や装置に組み込むことで、これまで経験者の勘や作業者の勘や目に頼ってきたことをAIに任せられるようになります。
1.2.1. 使用できるデータ形式
1.2.1.1. 時系列データ・振動データ
ファイルフォーマット: .CSV
詳細仕様
項目 |
内容 |
|---|---|
先頭行 |
先頭行は、必ず各カラム名(ラベル名)とする。 |
2行目以降 |
先頭行のラベル名に対応するデータを格納すること。 |
カラムのフォーマット |
カラムのフォーマットを統一させてください。 |
区切り文字 |
カンマ "," のみを使用のこと。 |
文字コード |
UTF-8のみ対応。(BOMあり。Excelが出力するCSVファイルはBOMありです。) |
ファイルの単位 |
異なるクラス(正常/異常など)のデータはcsvファイルを分けること。 |
注釈
振動データは周波数成分を取り出します。
ちなみに
CSVデータがMANUFACIAで使えるものかどうかを確認するには、CSVフォーマットチェッカを利用します。このツールでは各種のデータ加工も可能です。詳細はこちらをご覧ください。
1.2.1.2. 画像データ
ファイルフォーマット: .BMP .PNG .JPG
ヒント
JPG画像は非可逆圧縮のフォーマットですので、精度を上げたい場合にはBMPもしくはPNGフォーマットを推奨します。
撮像箇所のライティング状況も学習精度に影響します。また、注目ポイントが画像の一部であるような場合や、大きな一枚の画像から部分を切り出す必要がある場合には、データの水増しや加工をすることができる、データオーギュメンテーションツールを利用できます。詳細はデータオーギュメンテーションツールのユーザーマニュアルを参照してください。
1.2.2. MANUFACIAで作るAIモデル
1.2.2.1. AIモデルの種類
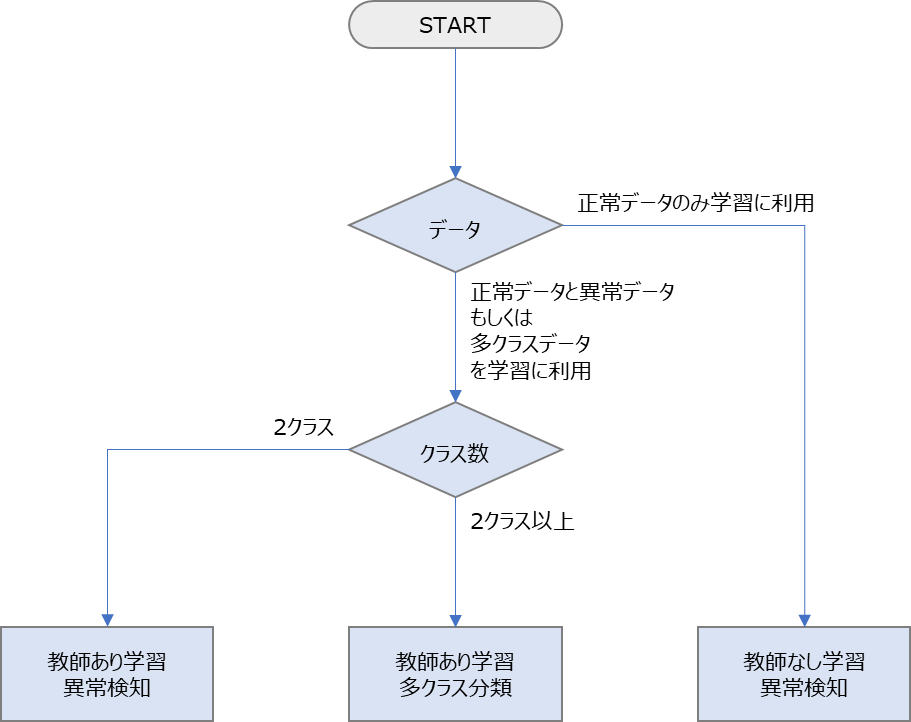
MANUFACIAでは、使用できる2種類のデータ形式(CSVファイル、画像ファイル)からタイプの異なる3種類のAIを生成することができます。その3種類のAIモデルについて以下説明をします。
教師あり学習 異常検知
異常検知を実行するためのモデルを生成します。「正常」「異常」両方のラベルのデータを学習に使うために教師あり学習と呼ばれます。生成したモデルのしきい値を調整できます。生成されたモデルを使うと、入力データが正常と異常のどちらに近いかを推論することができます。
教師あり学習 多クラス分類
2種類以上のラベルを付けたデータセットを使って多クラス分類モデルを生成します。生成したモデルのしきい値の調整はできません。生成されたモデルを使って推論すると、入力データが、モデル生成時に設定したラベル毎にそれに該当する確率を取得できます。
教師なし学習 異常検知
異常検知を実行するためのモデルを生成します。「正常」ラベルのデータのみ注を学習に使うために教師なし学習と呼ばれます。生成したモデルの距離(「正常と見なす範囲」)を調整できます。生成されたモデルを使うと、正常からどのくらいかけ離れているかを推論することができます。異常データが少ない場合に有効なアプローチです。
注釈
検証には「異常」ラベルのデータが必要です。
1.2.2.2. AIモデルの選定
重要
学習に2種類のラベル(「正常」と「異常」など)のデータセットを使う場合は、「教師あり学習 異常検知」を使ってください。
1.2.3. 作ったAIモデルを活用する
MANUFACIAで生成したAIは、デプロイという機能によりMANUFACIAからエッジ機器に送信することができますが、そのAIを操作するためのツールが用意されています。AIにデータを与えて推論をさせたり、結果を要求するためには、運用現場に合わせたシステムの開発が必要です。C言語用Greenia Embedded SDK(Software Development Kit)と、Python API (Application Programming Interface) があります。
1.3. AIの判定をどう評価するか
2値分類において正(Positive)と負(Negative)という言葉が使われますが、これは人間が自然に感じる良し悪しとは必ずしも一致しません。MANUFACIAが解決すると期待されている、製造現場の設備や機械の異常/故障は、人間には故障がないものが正常(良いこと)、故障があるものを異常(悪いこと)と考えられますが、AIがその正常と異常を判断するケースでは、そのAIが使われる目的が異常や故障を発見することですので、AIが異常や故障を発見することが正となり、発見できないケースを負と考えることになります。この場合は、正よりも負のケースが大変多くなります。
この正か負かの判断においては、正と判別された全てのもの、または負と判別された全てのものが全く同じということではなく、現実においても正と考えられるもの、負と考えられるものにも一定のバラツキがあり、その正の分布と負の分布が綺麗に分かれず重なり合っている場合に問題が生じます。
検査工程で製品の欠陥を見つけるケースを考えてみます。正の分布(青)と負の分布(赤)が重なっている場合に、万が一にも欠陥品が流通しないようにと下図のように正負の境界線を引き、その左側が正、右側が負としてしまうと、AIが正と判断したものに間違いはありませんが、正のはずの水色部分もAIに負と判断されてしまうことになり、良品を不良品として扱わないような事後検査などの無駄が生じることになります。
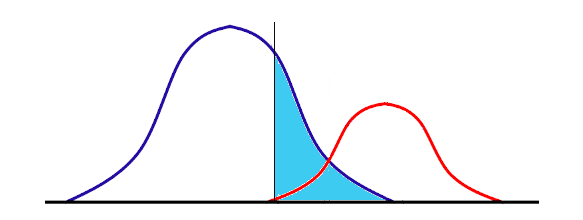
一般的なケースでは、その境界の引き方で、本来正なのに負と判断されるケース(水色)と、本来負なのに正と判断されるケース(ピンク)があり、状況に応じてこの境界線を調整する必要があります。

それ以前に大切なのは、学習をさせる際にこの正と負の分布がが出来るだけ綺麗に分かれているようなデータセットを準備して、このようなオーバーラップ部分を極力減らすことです。学習に使うデータセットが少な過ぎたり、実際のバラつきを反映していない場合はもちろんのこと、そもそもクラスの分類が正しくなされてない場合には、AIに良い判定を期待するのは難しくなります。
1.4. MANUFACIAを起動する
MANUFACIAはWebアプリケーションで、サーバー側でサービスを起動し、クライアント側のブラウザ上でサーバーにアクセスすることで操作をします。サーバー側でのサービスの開始については、インストールマニュアル -> インストールを参照してください。
クライアント側でブラウザを開いて下記のURLにアクセスします。インストールをされたIT担当の方からIPアドレスを聞いて、下記の{IP_ADDRESS}をそれに置き換えてアクセスします。
http://{IP_ADDRESS}:3200/
次の画面が表示されていればインストールしたアプリケーションは正常に動作しています。
1.4.1. 動作推奨環境
学習用GPUサーバ、クライアントPCについても、よくある質問(一般)-> 推奨ハードウェアスペックを参照してください。
1.4.2. 表示言語
ブラウザ表示言語の切り替えで、日本語/英語/韓国語/中国語_簡体/中国語_繁体 で画面表示されます。ブラウザ設定がこのどの言語にも該当しない場合には英語で表示されます。