3. MANUFACIAを使ってみよう2
MANUFACIAのプロジェクト作成は、以下の8つのステップで進みます。
プロジェクトの新規登録
AIモデルの種類を選択する
AIモデルの学習の仕方を選択する
使用するアセットのタグを選択する
ラベルを付与する
データを分割する
前処理を設定する
モデルを学習させる
3.1. プロジェクトの新規登録
アセットをすべて登録した後、【プロジェクト一覧】のタブをクリックします。
プロジェクトの【+新規作成】をクリックします。
プロジェクト名(必須)と概要(任意)を入力したのちに【次へ】をクリックします。
3.2. AIモデルの種類を選択する
生成するモデルの種類に合わせて、【異常検知】が【多クラス分類】を選択し、【次へ】をクリックします。モデルの種類についての詳しい説明はAIモデルの種類を参照してください。

3.3. AIモデルの学習の仕方を選択する
生成するモデルの学習の仕方に合わせて、【教師あり学習】か【教師なし学習】を選択し(図は教師あり学習の例)【OK】をクリックします。

プロジェクトが作成されていることを確認します。
3.4. 使用するアセットのタグを選択する
使用するプロジェクトの【アセットを選択】をクリックします。
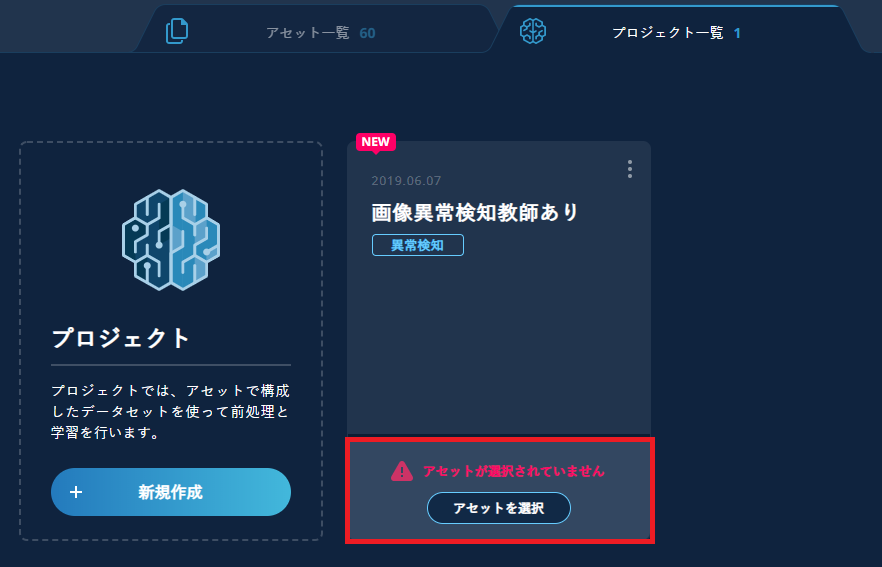
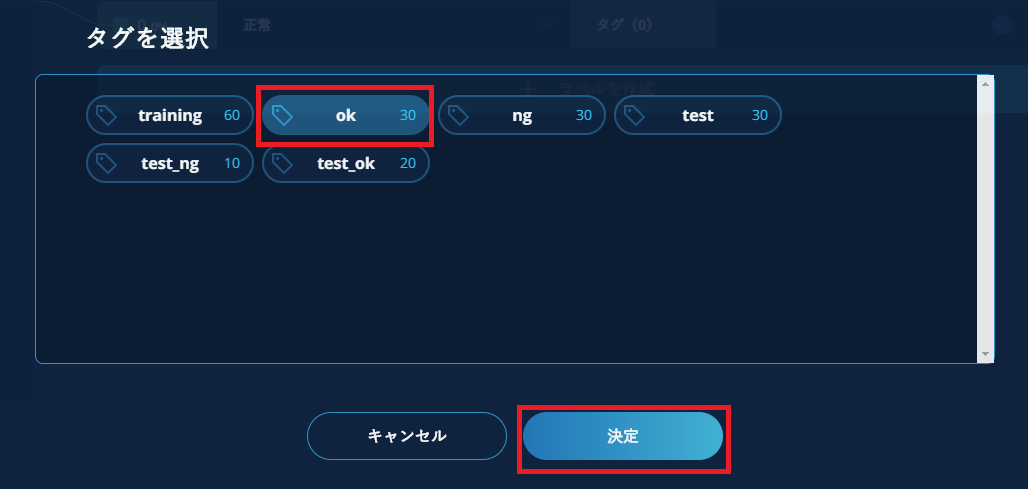
使用するアセットのタグを選択します。クラス分類用のすべてのタグ、および、学習データと検証データをアセットタグで分割した場合は「training」「test」タグも選択します。既出タグの設定例も参考にしてください。
使用するタグが全て選択されていることを確認し【OK】をクリックします。
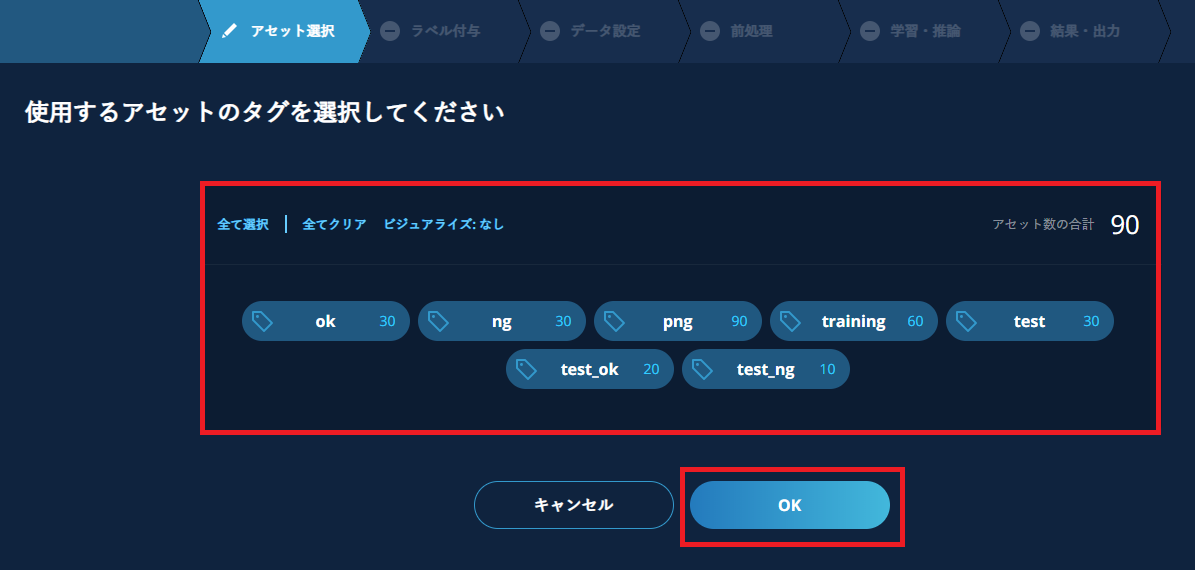
【ビジュアライズ】をクリックすると、各タグに紐づいているアセットの全体に対する割合がグラフ表示されます。
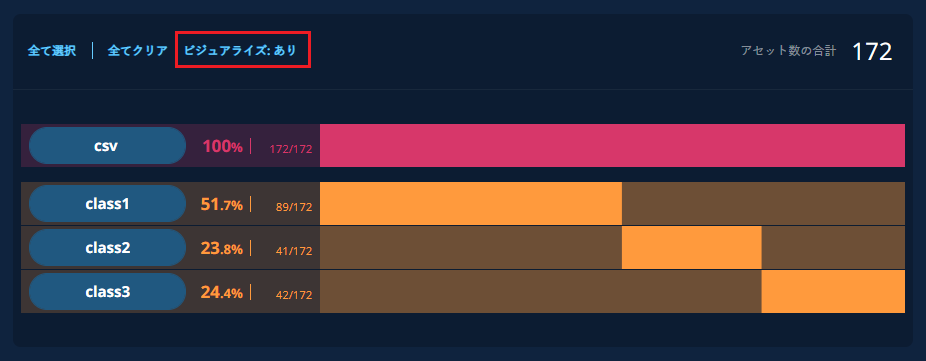
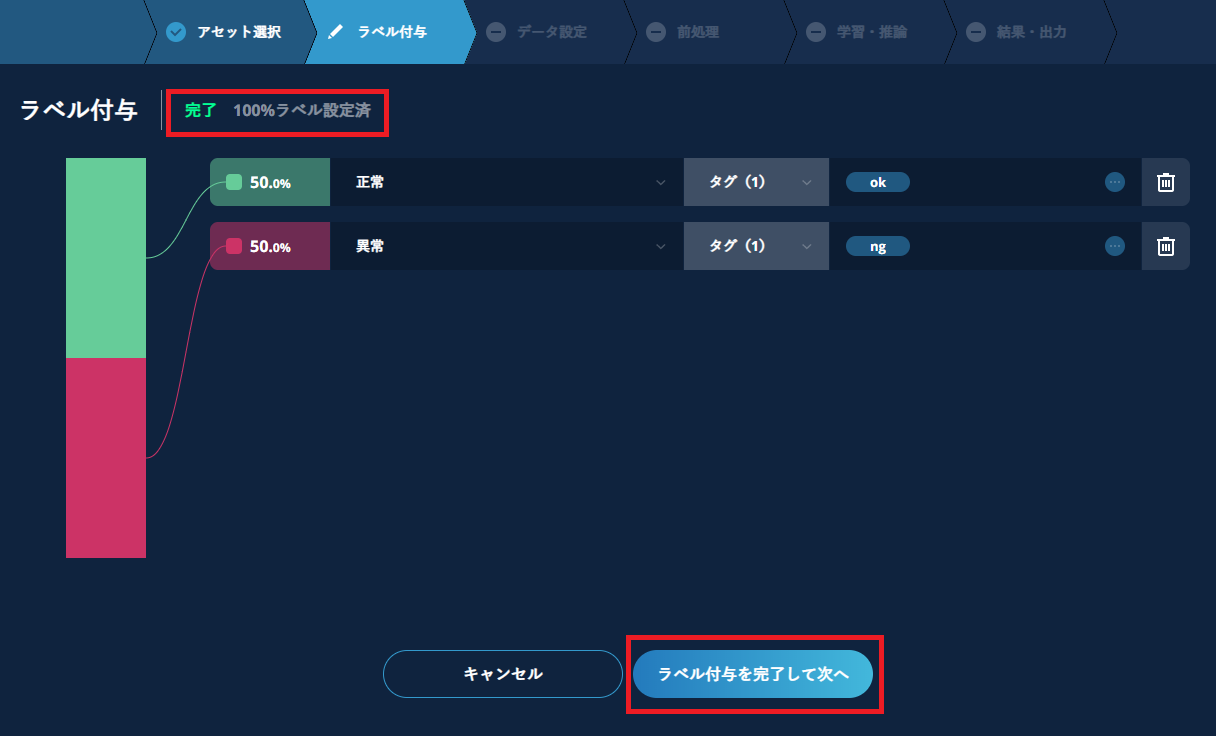
3.5. ラベルを付与する
前の工程で選択された、学習に使用するアセットのタグ毎にラベルを付けていきます。
画面の向かって右側でタグを設定し、その左側でラベルをリストから選択、もしくは文字入力(多クラス分類時)します。
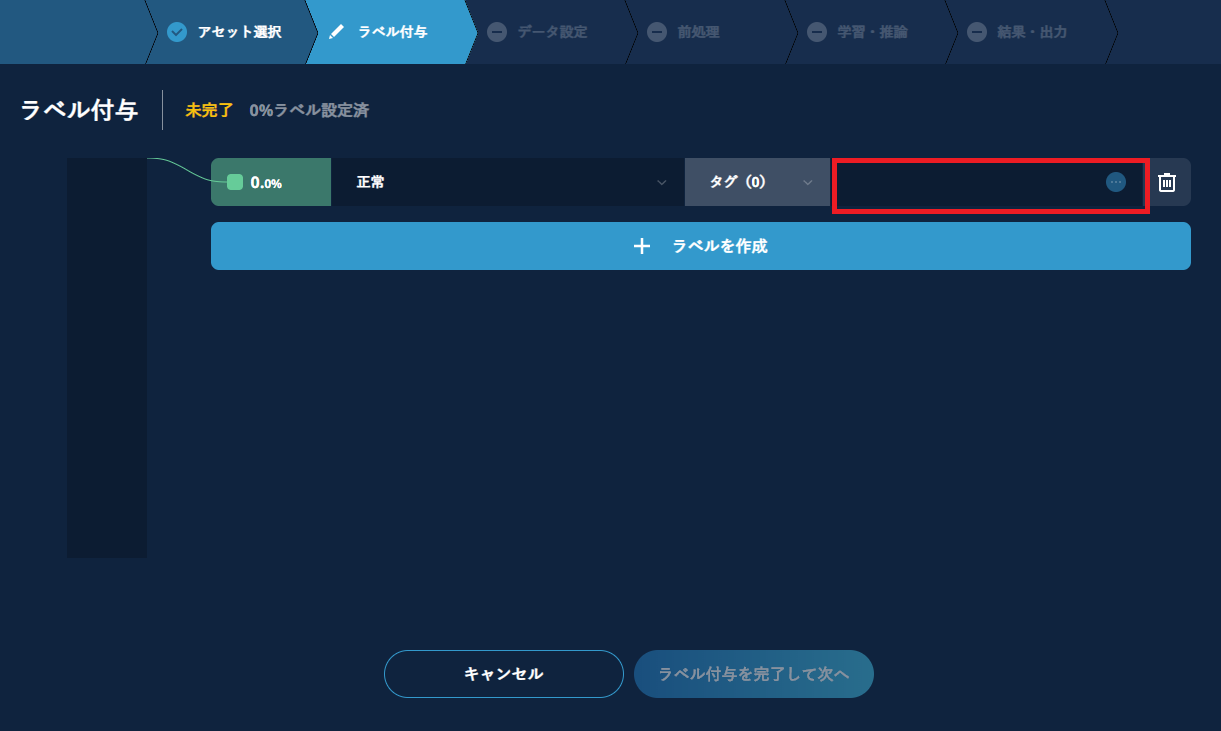
タグの設定は、タグの入力欄(ゴミ箱アイコンの左側のスペース)をクリックしたのちに表示されるリストから選択して行います。
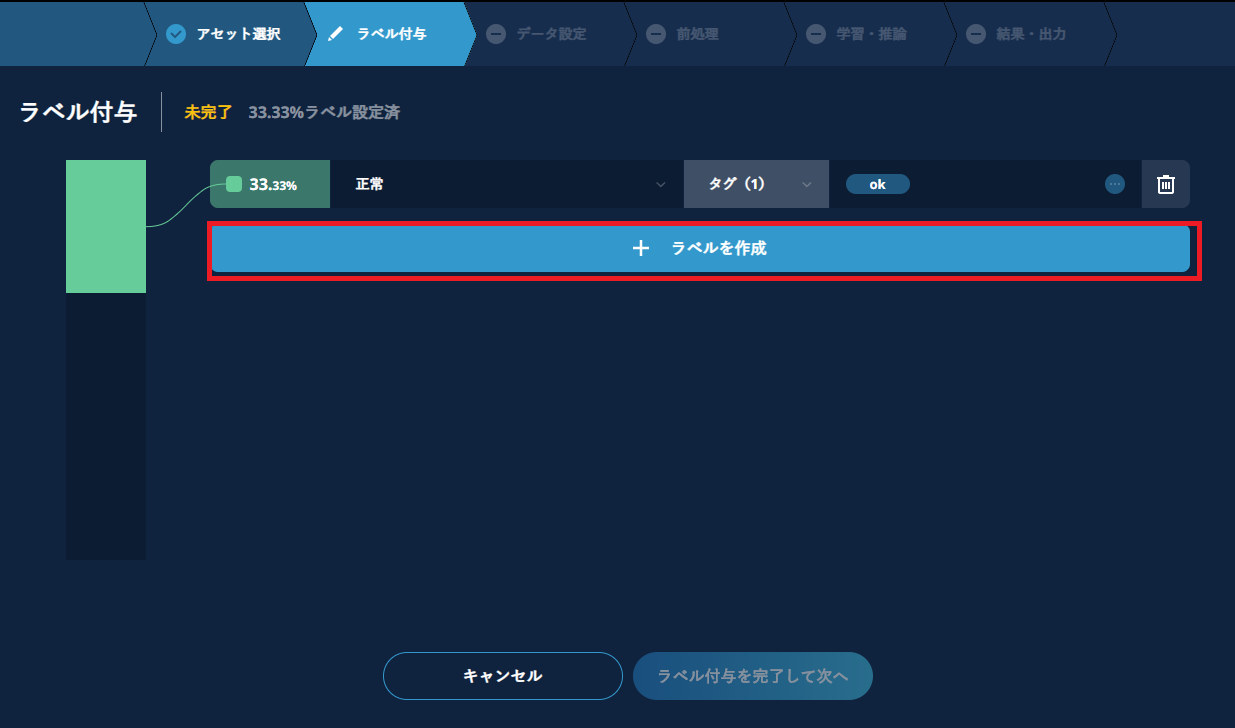
タグとして選択するのは、クラス(異常検知ではOKかNG、多クラス分類では果物毎の名前など)ですが、同じクラスであっても、学習用と検証用に分かれているものにまとめてラベルを付けることはできません。 正常や異常のデータが種類ある場合には、その種類ごと(クラス毎またはフォルダ毎)に正常または異常のラベルを付けてください。
初期画面では1クラス分しか定義できませんが、【+ラベルを作成】をクリックして入力欄を増やすことができます。全てのクラスについてラベル付与が終了すれば完了です。
ちなみに
各モデルにおいて、ラベルは最大20まで登録できます。
注意
ラベルには半角カナは使用しないでください。学習エラーとなることがあります。
複数のタグを選択した場合は、どちらも満たした(AND 条件の)アセットが対象となります。
重要
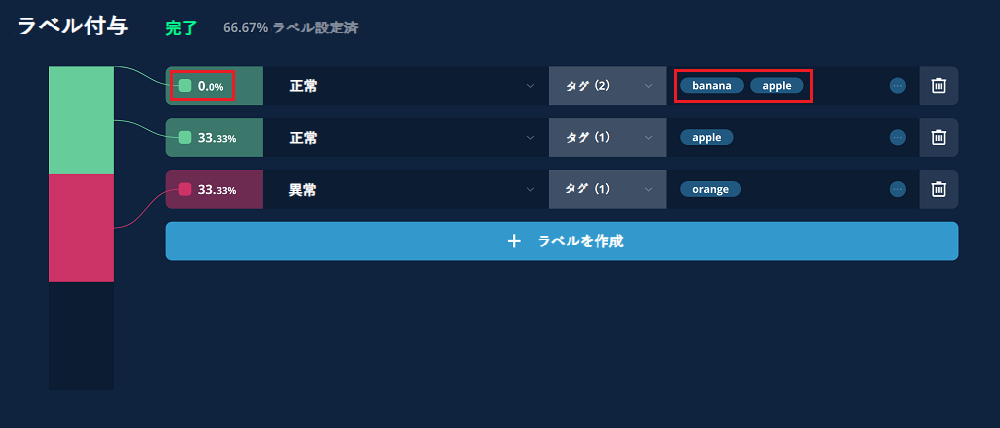
全てのラベルにおいて、アセット割合が0%ではないことを必ず確認してください。割合表示が0%になるのは、1つのラベルに複数のタグが選択されており、そしてその全てのタグに紐つけされているアセットの共通部分がない場合です。
アセットの登録時のタグ付けに間違いがなかったか、ラベル付与時の操作ミスがないことを確認し、ラベル付与をやり直してください。
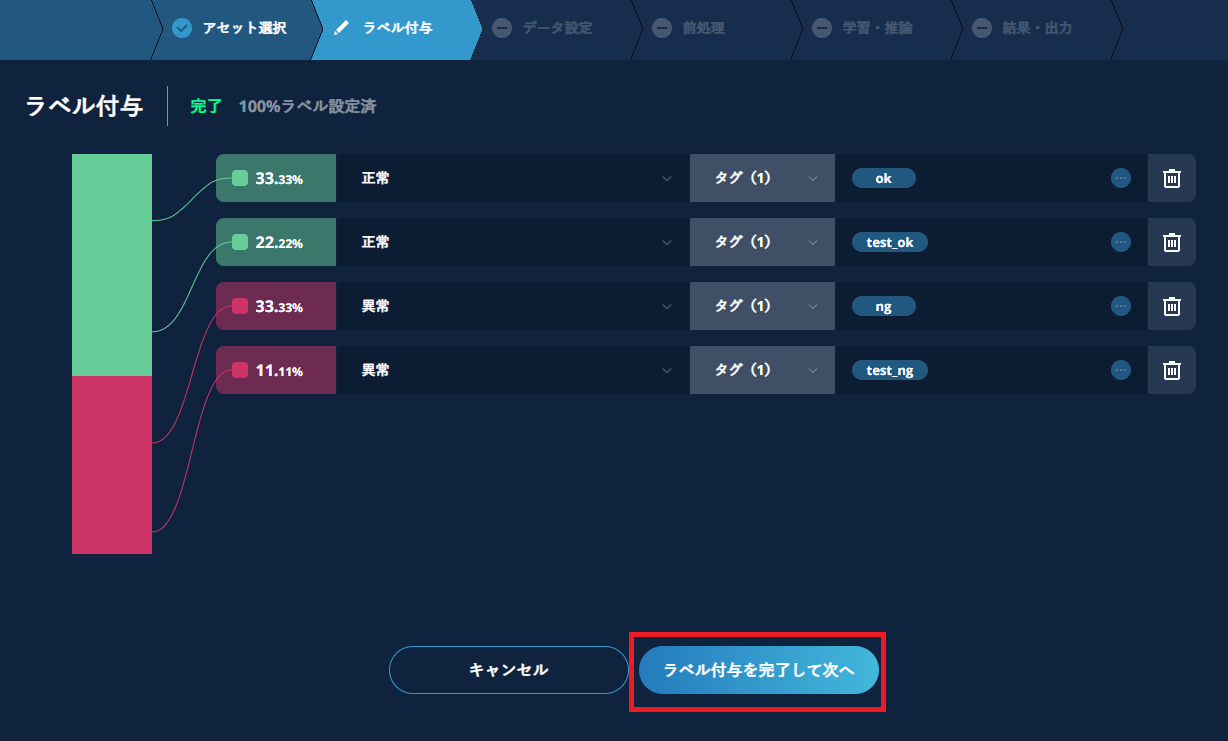
3.5.1. ラベル付与例
異常検知教師ありの設定例
異常検知教師なしの設定例
多クラス分類の設定例
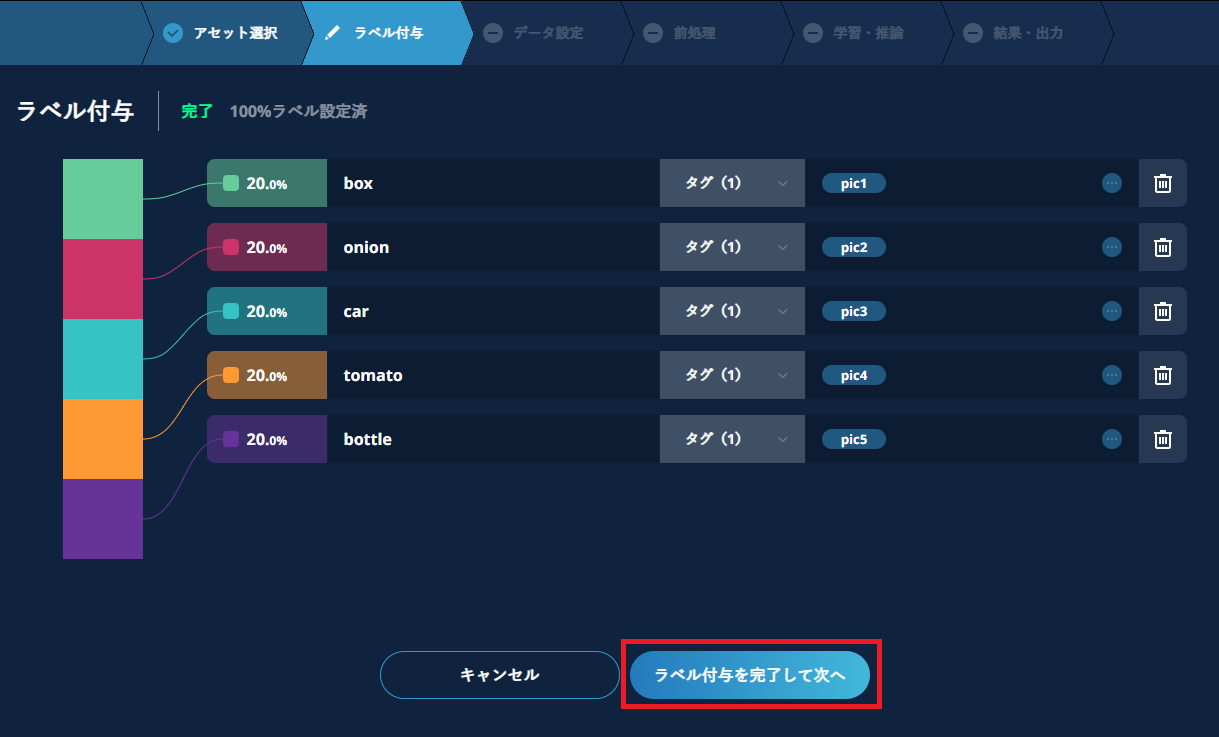
全てのクラスのラベルとタグ設定が終了後、【ラベル付与を完了して次へ】をクリックします。
注意
ラベル付与の%表示は、ラボに登録されている全アセット数を100とした場合の割合です。ラボに登録されているデータをすべて利用しない場合は、ラベル設定済みは「100%」になりませんが問題ありません。
教師なし学習の場合は、異常のラベルに「training」タグを紐付けすることはできません。学習エラーとなります。
タグやラベル付与が未完全(付与されていない、もしくは%表示が0)のまま次へ進むと、学習エラーとなります。
3.6. データを分割する
学習データと検証データを分割します。アセットの登録時に、学習データと検証データを分けている場合には【アセットタグで分割】を、学習データと検証データを分けておらず、それぞれを入力した値で按分する場合には、【割合で分割】を選択し、【データ分割を行う】をクリックします。
図は【割合で分割】を選択する場合の例です。
重要
アセットタグで分類する場合は、アセットの登録時に「training」「test」タグが選択されていなければならず、一旦登録したものを後で修正することはできません。タグの設定例を参照してください。
3.6.1. アセットタグで分割
学習用データに【training】タグを、検証用データに【test】タグを選択します。

バーチャートで、学習用、検証用に正しく分割されていることを確認し【次へ】をクリックします。

3.6.2. 割合で分割
バーを動かし、学習用データと検証用データの割合を決定します。 ここでは例として、正常ラベルに対応するタグは2種類、異常ラベルに対応するタグは2種類設定しています。 割合の設定が完了したら【次へ】をクリックします。

3.7. 前処理を設定する(時系列、振動データ)
振動データは一般的な時系列データとは違い、原動機などと接続された設備や装置において工程が周期的に繰り返されることで起こる振動や異音などの事象を扱うものです。時系列データの前処理に加え、以下の設定が可能です。
スライディングウィンドウ
窓関数
FFT処理
3.7.1. CSV読込
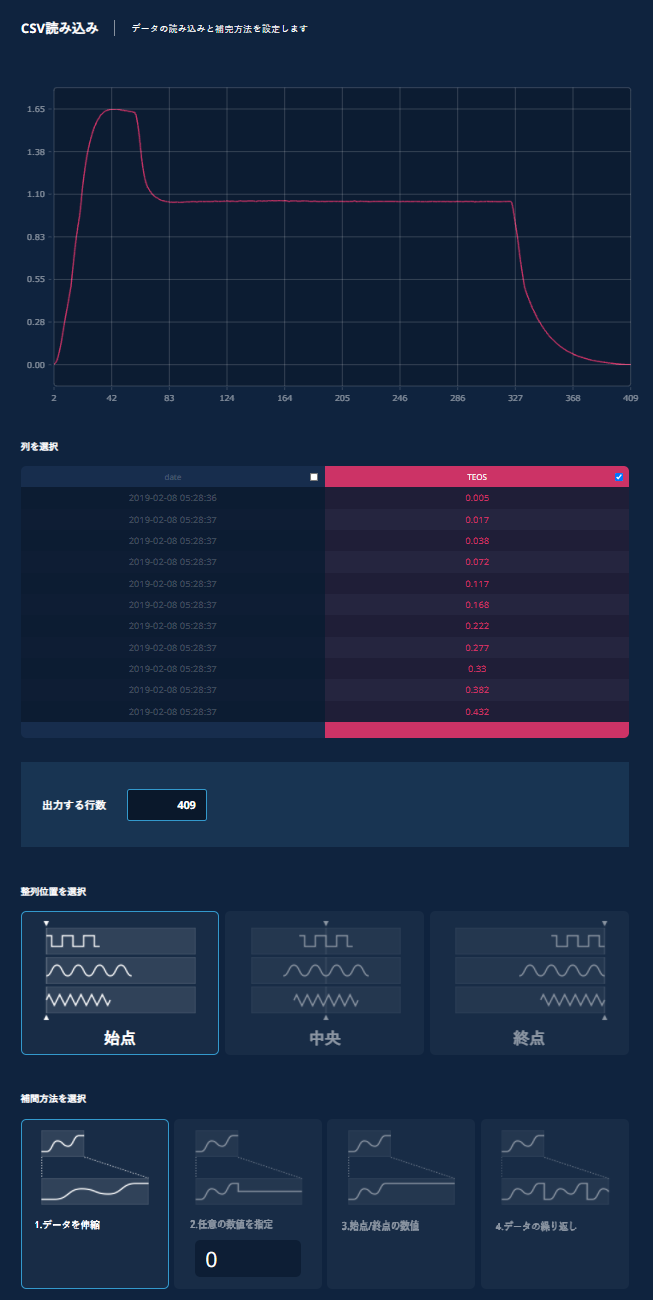
入力ファイルのどの部分を読み込み、修正して、学習に使用するかを設定します。
読込列:
学習時に考慮する入力データの列(複数可)を選択します。
出力行数:
データアライメント:
インターポレーション方式:
この3つの設定の組み合わせにより、元データの前方/後方部分をトリミングしたり、短い入力データを繰り返すような長いデータを学習に使用することができます。補間方法は、整列位置の選択項目に連動して変わります。
ケース1:CSVデータの前方をトリミングしたい場合
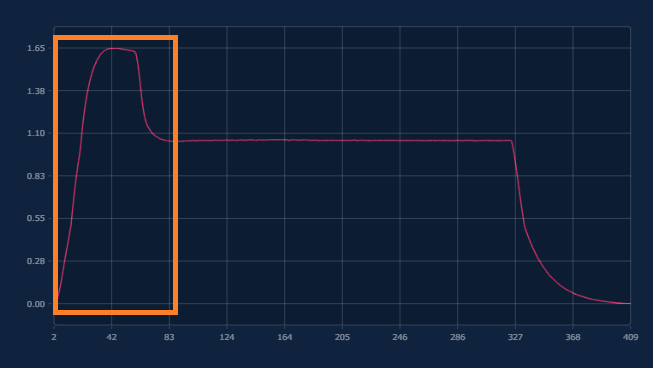
a) データの元々の行数からトリムしたい部分の幅(行数)を引き、出力する行数に入力する。(409 -> 320)
b) 整列位置を終点にする。
c) 補間方法を2, 3, 4のいずれかにする。
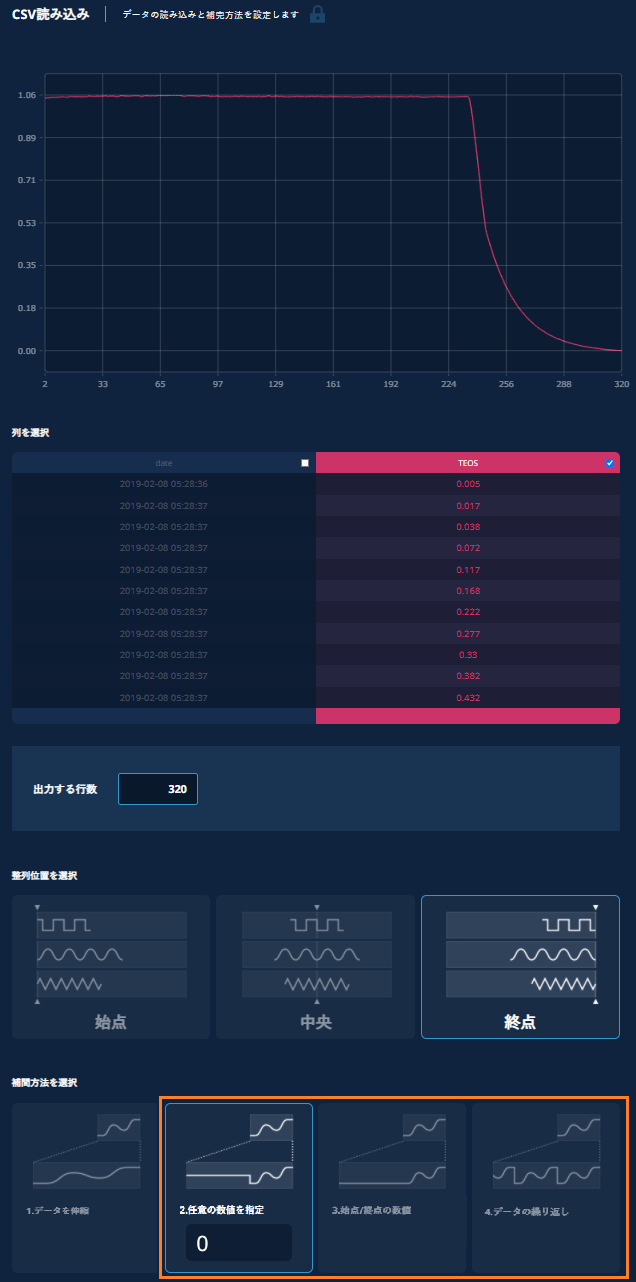
ケース2:CSVデータの後方をトリミングしたい場合
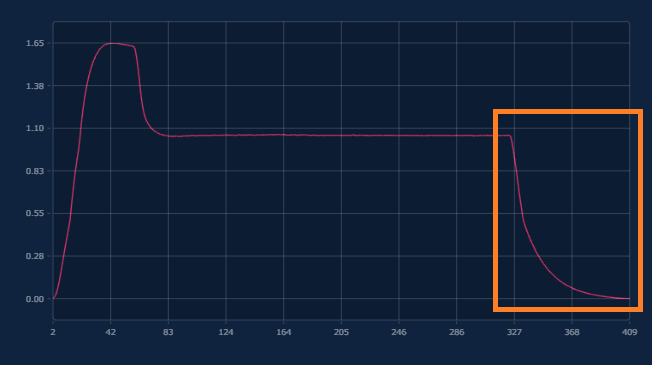
a) データの元々の行数からトリムしたい部分の幅(行数)を引き、出力する行数に入力する。(409 -> 320)
b) 整列位置を始点にする。
c) 補間方法を2, 3, 4のいずれかにする。
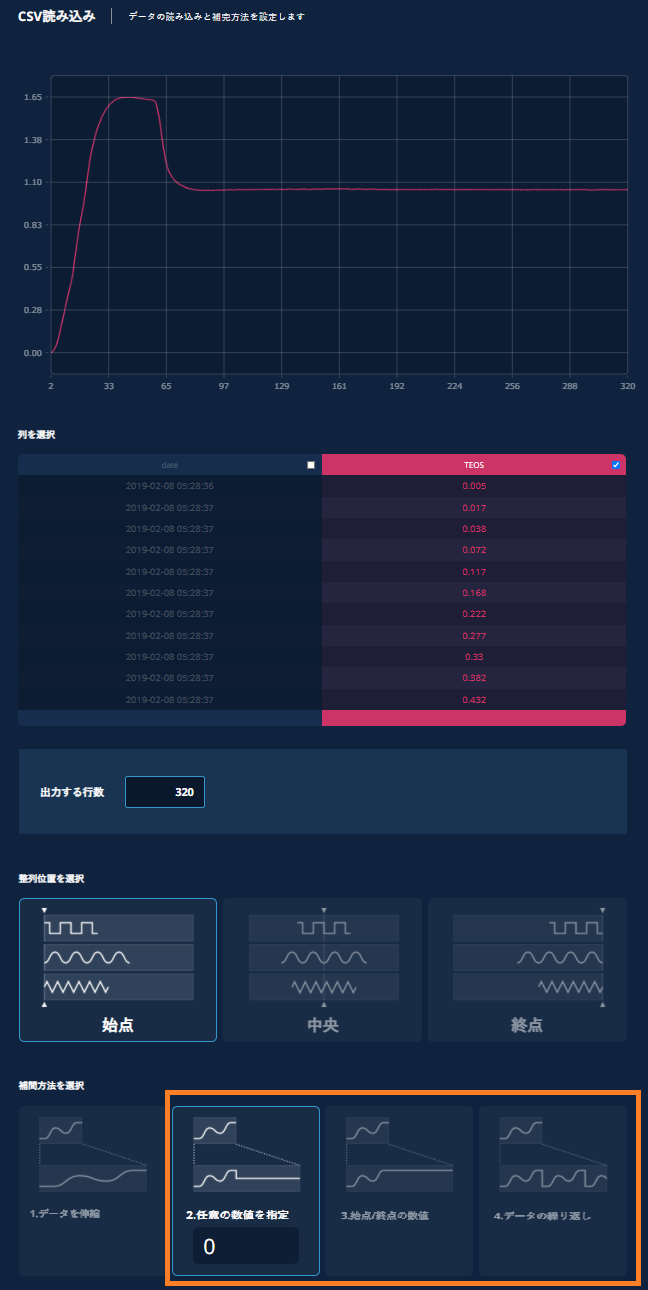
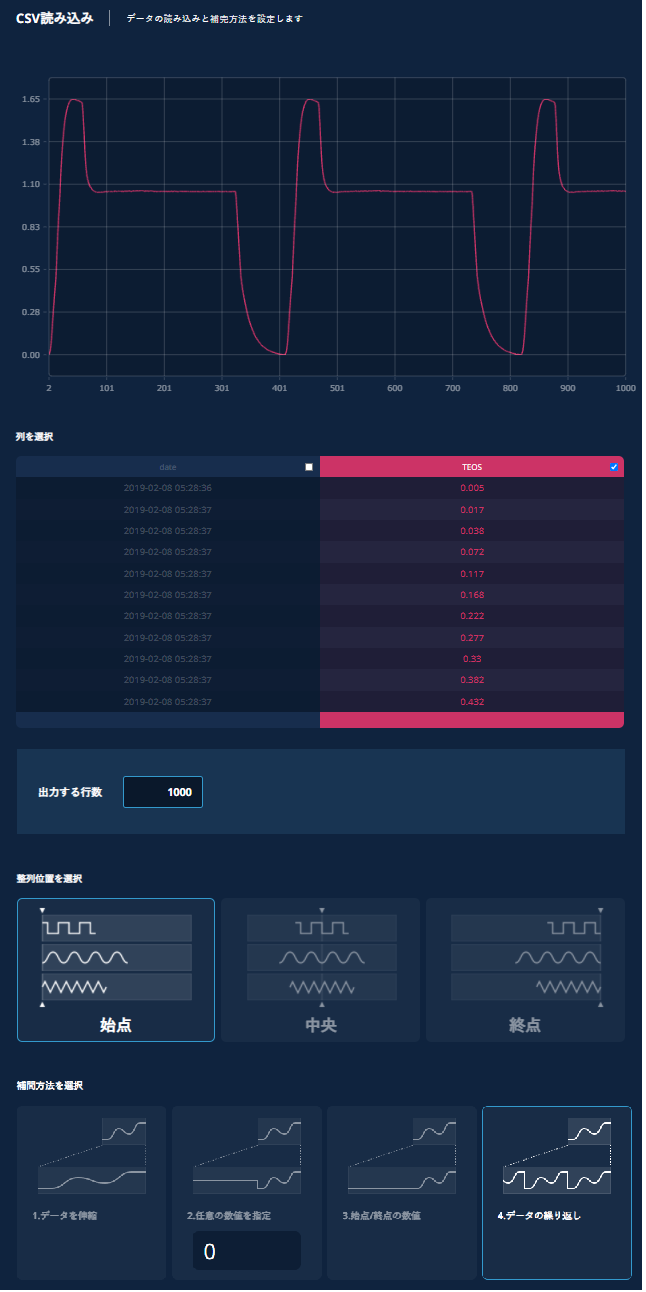
ケース3:短いCSVデータをデータの繰り返しにより伸長したい場合
a) データの元々の行数よりも大きな値を出力する行数に入力する。(409 -> 1000)
b) 整列位置を始点にする。
c) 補間方法は4.データの繰り返しを選択する。
ちなみに
もっと複雑な処理が必要な場合には、CSVフォーマットチェッカーをご使用になることで、特定の開始行から終了行までの抽出、データの間引きなども可能です。詳しくはこちらを参照ください。
3.7.2. クランプ(オプション)
データを取り込む際の上限値と下限値を設定することでノイズを除去します。設定値はそれぞれ最大256、最小-256です。
3.7.3. スライディングウィンドウ( 振動データのみ )
スライディングウィンドウの設定にはデータ分析の知見が必要となりますが、数値をどのように調整して試せばよいのかの方針を説明します。
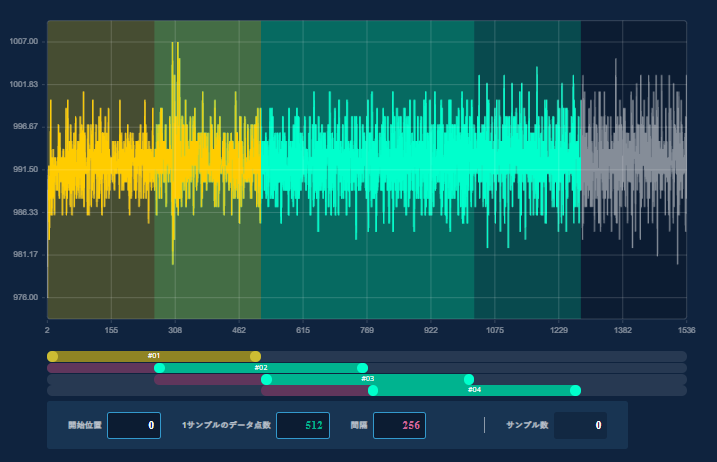
1サンプルのデータ点数:
1.「512」の初期値。
2.「256」の値。(半分)
3.「1024」の値。(2倍)
4. 全データの値。
これらのうちのどこで一番良い精度が出るかを見つけ、その設定を使います。
間隔:
上記の1サンプルのデータ点数の1/5から1/10の程度の範囲。
注意
1サンプルのデータ点数の初期設定の512よりも短いデータを使う場合には、設定をデータ点数よりも小さくしないとエラーになります。データ行数の1/4を目安に設定してください。
1サンプルのデータ点数とインターバルを適切に設定することで、波形全体がグレーではなく、緑や黄色の連続する帯状の領域が表示されることを確認してください。
3.7.4. 窓関数( 振動データのみ )
窓関数はスペクトル解析、デジタルフィルタ、音声圧縮にも使われるものです。MANUFACIAでは以下の2つの窓関数が用意されています。両方のオプションでどちらが良い精度になるか試してみてください。
Gauss:(初期設定)
この関数はv2.2以降のバージョンでリストから外れる予定です。
Hamming:
以下のHann窓と並び、最もよく使われる窓関数の一つ。Hann窓の改良版として考案されたもので、より周波数分解能が高くダイナミックレンジが狭いが、Hann窓と違い区間両端でゼロとならないために不連続となります。
Hann:
この関数の特徴は、区間の端に向かってなだらかに小さくなっていき、両端は必ずゼロになることです。正弦波をフーリエ変換した場合のスペクトルは、矩形窓を使う場合に比べてピークがはっきりと現れます。
3.7.5. ノーマライズ/スタンダーダイズ
ノーマライズ(正規化):(初期設定)
正規化を行うことで、ファイル毎のデータのバラツキを吸収することができます。
処理の内容は、入力データの絶対値の最大値で各データを割ることでデータの範囲を-1.0から1.0になるようにデータを変換します。
データの中に外れ値(異常値)が含まれるような場合には正規化はその影響を受けやすくなりますので、扱うデータセットに外れ値がないことを確認してから使ってください。
スタンダーダイズ(標準化):
標準化を行うことで、データの平均と分散を考慮することができます。ノーマライズよりも良い結果が出るケースもあります。
画像データでは、画面全体的に単調で変化が少ない場合にそれを際立たせることができます。
処理内容は、ノーマライズ処理の後、自動設定では平均値が0.0、標準偏差が1.0となるようにを入力データを変換します。データの平均値μや標準偏差σが既知の場合には、マニュアル設定で入力することもできます。変換後の数値n’は、元の数値をnとすると以下のように変換されます。
n’ = (n - μ) / σ
3.7.6. FFT処理( 振動データのみ )
高速フーリエ変換の略称で、MANUFACIAでは時系列の信号の周波数分析をします。窓関数と組み合わせて使います。
3.7.7. インターポレート(オプション)
どのようにデータを間引いたり補ったりするかを設定します。モデルの精度を出すためには、最初はオフにしておくことをお勧めしますが、オンにすることで良い精度が出る場合もあります。
元々の長さが1000のデータをこの設定により200とする場合には、データが1/5に圧縮されることになります。データが少なることで学習が速くできます。(初期値:100)
liniear:最寄りの2点間を線形補間し、点の間隔の割合に応じて新たな要素を生成します。(初期設定)
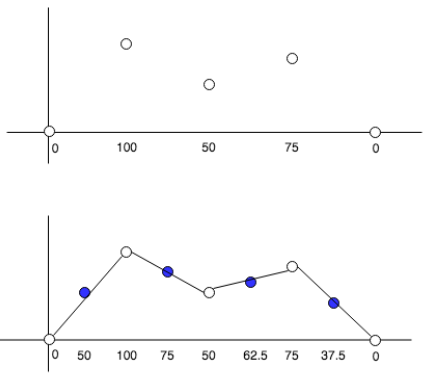
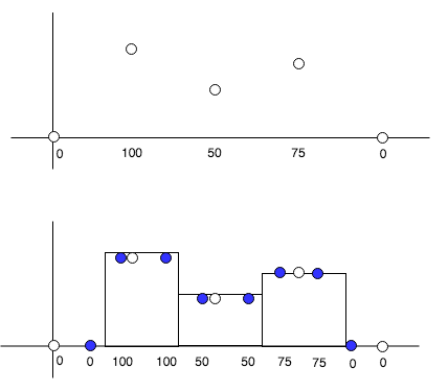
nearest:新しく作られる要素は、最寄りの点の中で一番近い点の値で生成されます。
3.7.8. バイナライズ(オプション)
入力をしきい値(0.0から1.0の範囲)で2値化(0もしくは1)します。特徴量が分かりやすく表示されるものには設定した方がいいですが、時系列データ、振動データには使わなくても構いません。
3.7.9. バッチ処理
バッチサイズとは一回の学習で使われるデータの数のことです。ディープラーニングでは損失関数を最小化してパラメータに適切な重みづけをするために勾配降下法という手法が使われますが、リソースの関係でコンピューターに一度に全てのデータを渡せないため、このようにデータセットを小さなサイズに分けて学習に用います。
バッチサイズが比較的小さいと、1つのデータから受ける影響が大きくなり、特徴的、もしくは平均的ではないデータがあった時に受ける影響が大きくなります。バッチサイズが比較的大きいと、その影響を受けにくくなります。とはいえ、一概にバッチサイズが大きければよいというものでもありませんが、通常は2^n乗の数値が使われます。(初期値:4)
バッチサイズは、アセットサイズやハードウェアのRAMによっても上限が決まります。学習誤差曲線も参考にしてください。
3.8. 前処理を設定する(画像データ)
3.8.1. 画像読込
画像サイズ:
入力画像を指定した大きさにリサイズします。形状は縦横が同じ長さの画像を想定しています。初期設定は224 x 224となっており、この設定以下のサイズの画像を学習させると、教師あり学習の場合に高い精度が期待できる学習済みモデルを使用することができません。大きなサイズの画像を使うと学習に時間が掛かります。512 x 512が上限値として設定されています。
表示方法:
この表示方法の選択は、入力画像データの幅と高さが同じではない場合に適用されます。
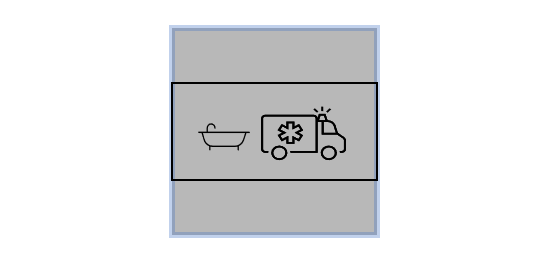
distort:画像の縦横比を維持しないで出力画面サイズに合わせます。
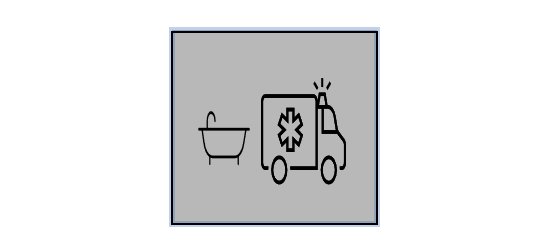
cover:画像の縦横比を維持したまま、縦横の辺の短い方を出力画面サイズに合わせ、画像の中央部分を切り取ります。
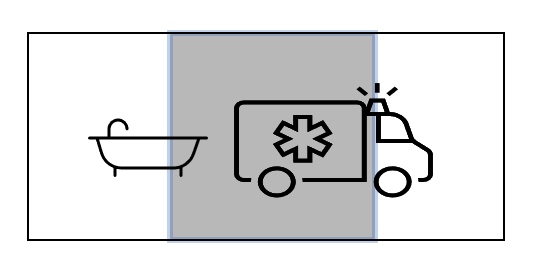
contain:画像の縦横比を維持したまま、縦横の辺の長い方を出力画面サイズに合わせ、元画像以外の部分には黒い背景を埋め込みます。
アルゴリズム:
bilinear:X、Y軸の両方で線形補間をおこないます。
nearst-neighborbor:画像はガタガタになりますが、処理を軽くすることができます。bilinearとの精度の比較は単純にはできません。
3.8.2. グレースケール/チャンネル選択
入力画像のカラーチャンネルを選択します。
グレースケール:グレースケール(白黒)で扱いたい場合に選択します。
注意
この選択をすると、チャンネルが自動的にRのみになります。
チャンネル選択:入力画像のチャンネルをRGBのうちから選択できます。(初期設定)
3.8.3. 切り抜き(オプション)
入力画像、を画像の中心を基点に指定された大きさ(正方形)で切り取ります。中央に映っている興味の対象以外を全て除きたい場合に使います。
3.8.4. ノーマライズ/スタンダーダイズ
時系列、振動データの同項を参照してください。プレビューを見ながら、より特徴量が出るように調整していくことをお勧めします。
3.8.5. バイナライズ(オプション)
時系列、振動データの同項を参照してください。
3.8.6. バッチ処理
時系列、振動データの同項を参照してください。
3.9. モデルを学習させる
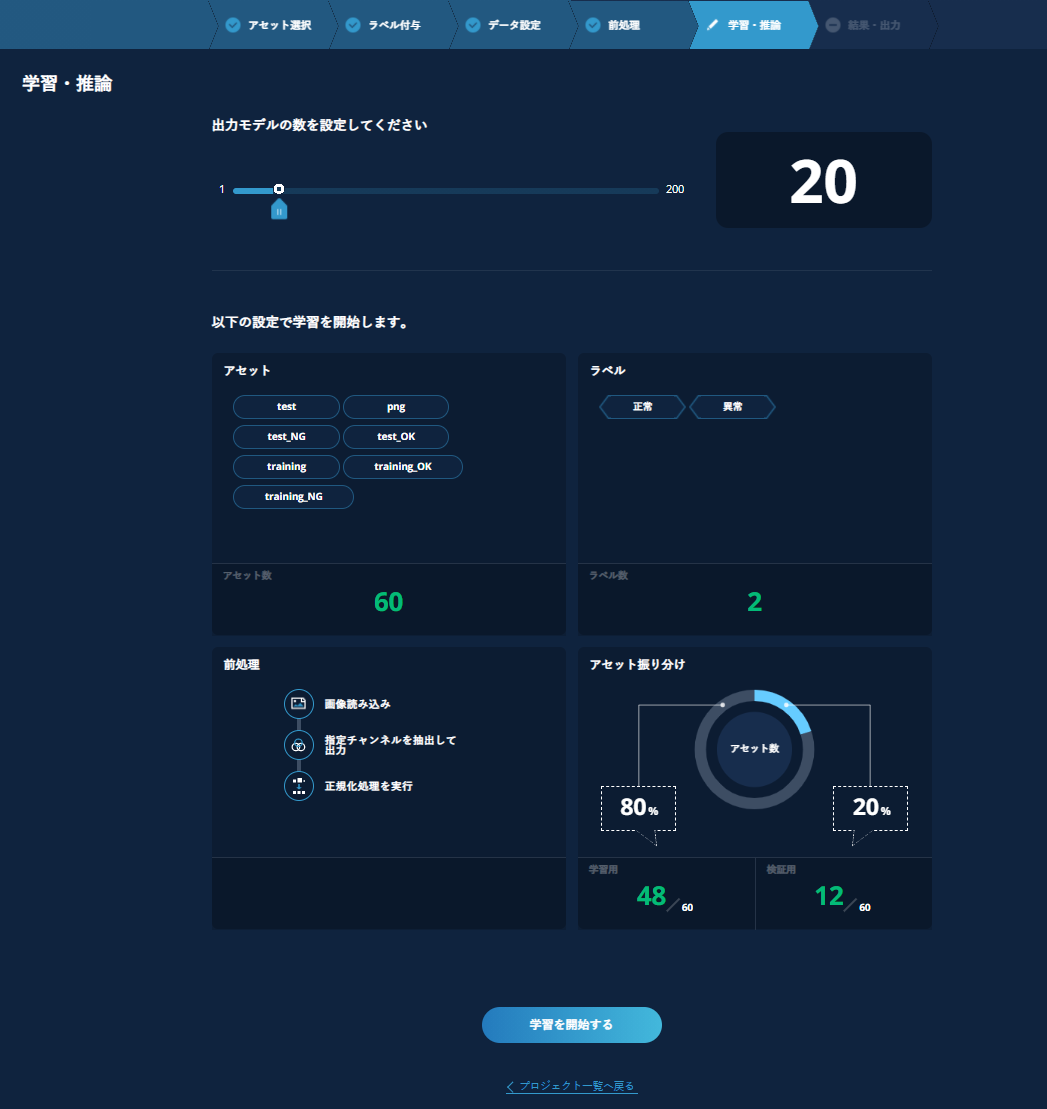
バーを動かして出力モデルの数を設定します。最大200モデルの生成が可能です。
画像の教師あり学習では、事前学習済みのResNet50とMobileNetV2を使ってモデルを作成できます。既存のニューラルネットワーク(CNN)よりも優先的に使用されるため、モデル数を2に設定した場合にはCNNは使われず、ResNet50とMobileNetV2を使ったモデルがそれぞれ1つずつ学習に使われます。
ちなみに
ResNet50とMobileNetV2のモデルは、CNNネットワーク同様、学習に失敗することがありますので、必ずしも生成されるわけではありません。
出力モデルの数が設定できれば【学習を開始する】をクリックします。
ちなみに
【学習を開始する】ボタンを押しても画面が変わらない場合に、再度ボタンを押すと学習エラーと表示されることがありますが、学習の進捗を正しく表示できるようになると、学習の進度を表す円グラフが現れます。
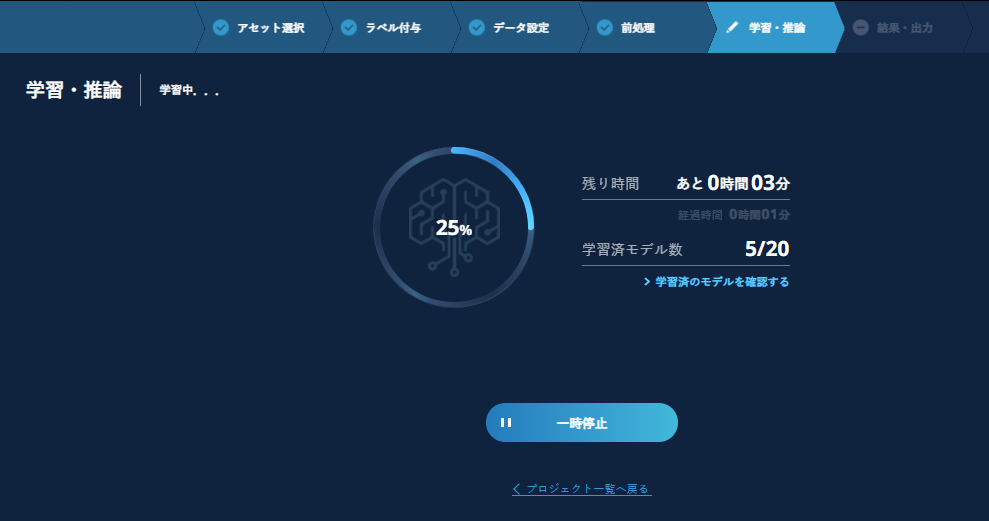
学習が始まると、画面には学習の進度が表示されます。【一時停止】を押すことで学習を一時停止することができます。
ちなみに
この一時停止は、学習を既に開始したバッチジョブを中断するのではなく、これから学習をスタートさせる予定のバッチジョブを待機させておくという仕様になっています。作成するモデル数にも寄りますが、学習がかなり進んだ状況、モデル数が少なければ80%、多ければ90%以上で一次停止を押しても、一時停止状態にならないこともあります。
また、【学習済みのモデルを確認する】をクリックすると、その時点で作成されたモデルを確認できます。
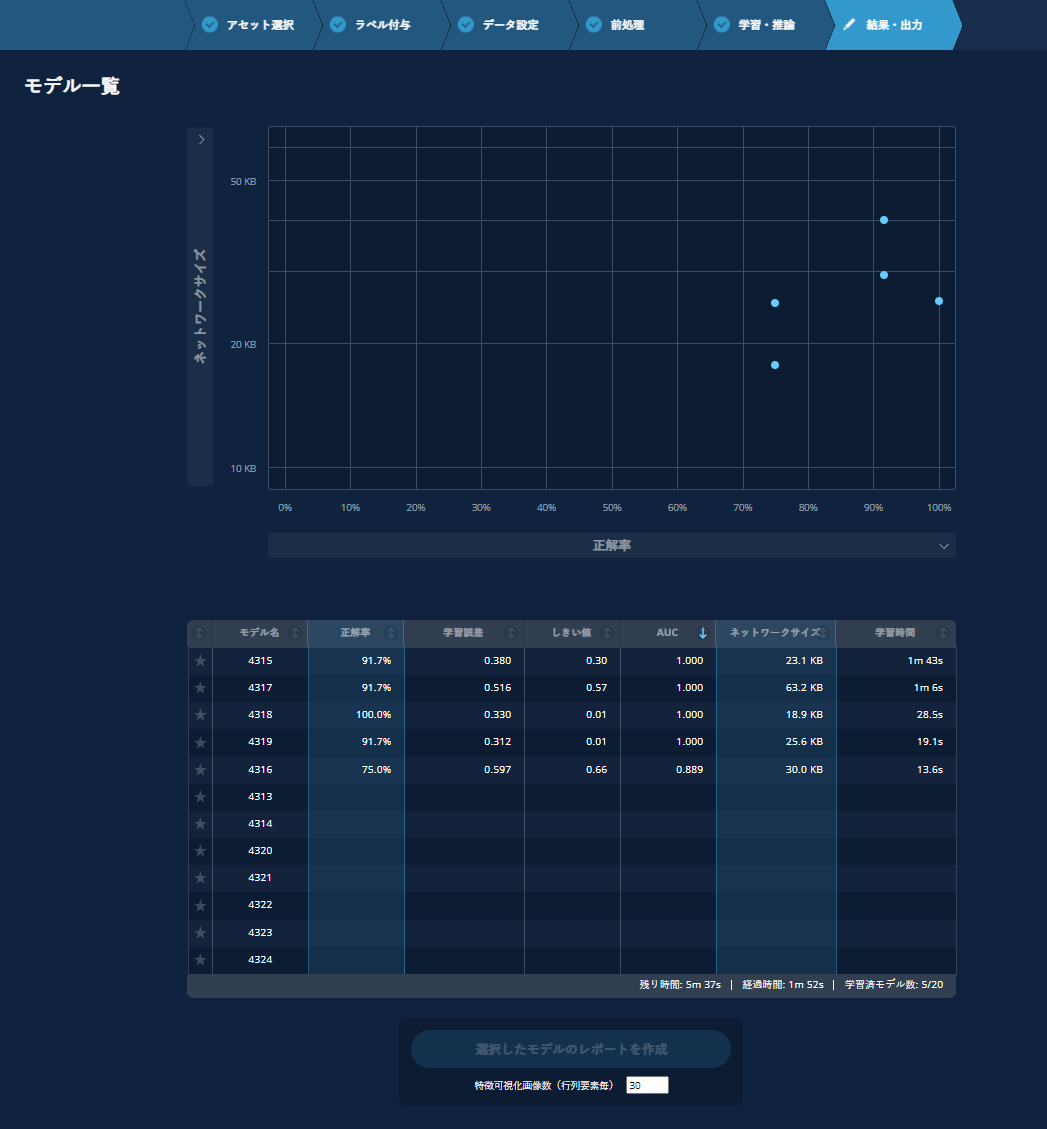
以下のように作成済みのモデルが表示されます。ナビゲーションバーの【学習・推論】をクリックすると学習画面に戻ります。
ちなみに
各モデルの学習は並列処理で行われているため、全モデルの所要時間を合計しても学習開始から終了までの時間にはなりません。
学習が終わると、詳細結果を表示することができます。
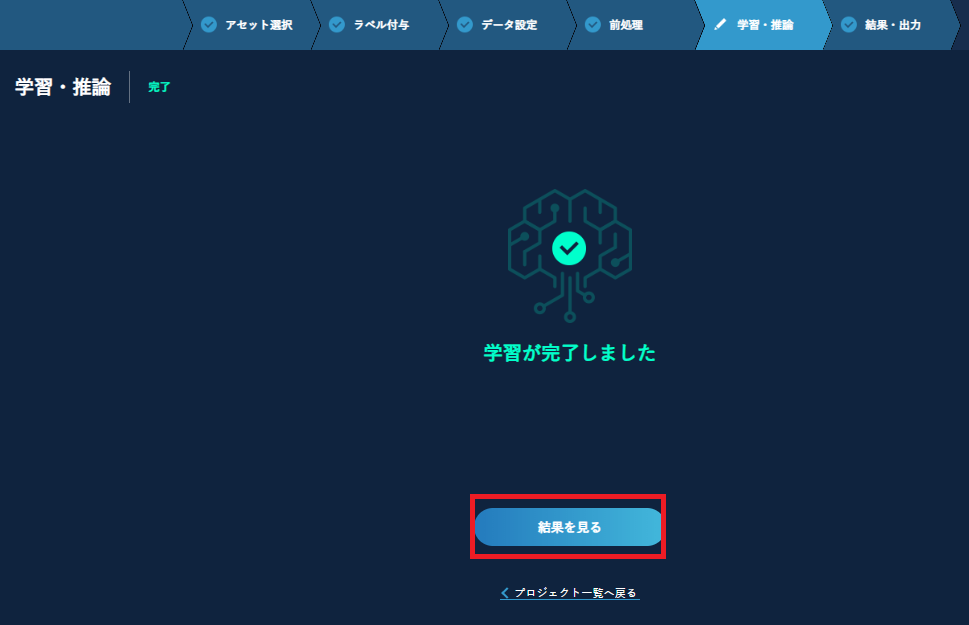
ちなみに
プロジェクトの学習結果を初めて表示する時には、しきい値や距離計算のために、特に検証データ数が1000を超えるような場合にはモデルリスト表示までに時間がかかることがあります。